
Why and How to Migrate from Vaultless Tokenization to a Vault
Many companies rely on legacy vaultless tokenization solutions to protect sensitive data, but this approach has certain limitations in terms of data privacy, maintainability, and compliance. So, how can you migrate away from vaultless tokenization tools without impacting business operations?
As businesses handle increasing amounts of sensitive data like names and social security numbers, they need flexible tokenization solutions to help them protect this data. One of the more popular legacy solutions for tokenizing sensitive data is vaultless tokenization, but this approach tends to require extensive customization and maintenance.
Worse yet, it doesn’t help companies who need to honor data residency requirements so that they can grow and expand into new markets while preserving data privacy. It also doesn’t provide data governance or state-of-the-art data obfuscation that’s up to the challenge of protecting sensitive data from malicious actors as required by standards like PCI DSS. These limitations are why we recently migrated a company that was using vaultless tokenization for hundreds of millions of records to a zero trust data privacy vault architecture (with zero downtime).
In this blog post, we’ll explore the limitations of vaultless tokenization when compared to using the tokenization capabilities provided by a zero trust data privacy vault. We’ll also look at the challenges involved with migrating away from vaultless tokenization, and how bring-your-own-token capabilities can help you overcome these challenges and seamlessly migrate to a better solution – without impacting your business.
Tokenization, Encryption, and Vaults
Before delving into the differences between vaulted and vaultless tokenization, let's clarify what tokenization is and how it differs from encryption. Tokenization is generally defined as a non-algorithmic approach to data obfuscation that swaps sensitive data for non-exploitable strings called tokens.
For example, if you tokenize a customer’s name, like “John Doe”, it gets replaced by an obfuscated (or tokenized) string like “d7-4c-5734”, meanwhile the original sensitive data (the string “John Doe”) is stored in a vault, as shown below.
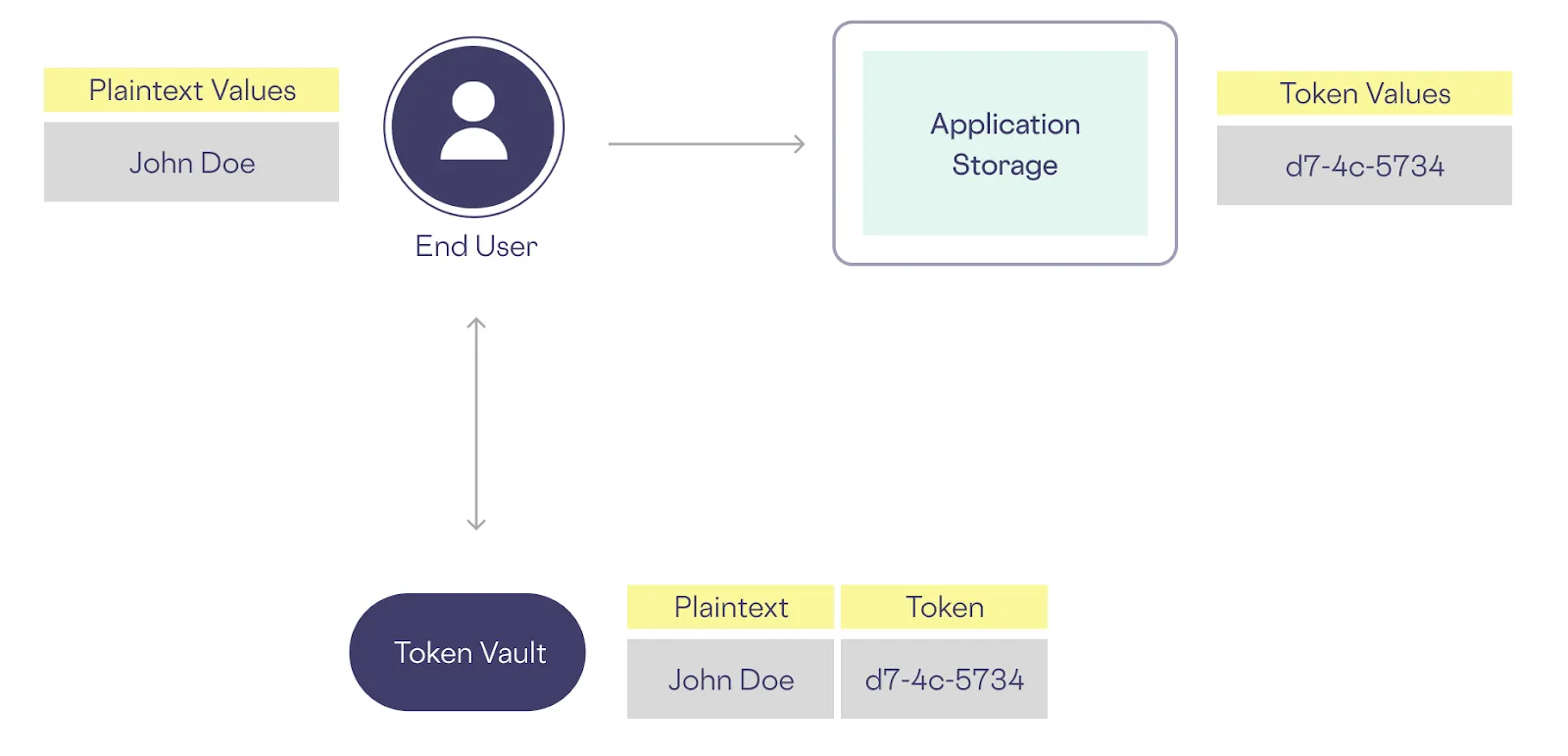
Because there’s no mathematical relationship between “John Doe” and “d7-4c-5734”, even if someone has the tokenized data, they can’t get the original data from the token without access to the tokenization process. And just as importantly, even if a malicious actor discovers that this token (d7-4c-5734) corresponds to “John Doe”, that doesn’t help them to get the names of other customers from their tokens.
For example, let’s say that you tokenize the following three names:
Because these names are tokenized, and there’s no relationship between each name and its corresponding token, cracking a single token has no impact on the security of other tokens. The sensitive data values remain safely stored in a vault.
Comparing Tokenization to Encryption
Unlike encryption, tokenization doesn't use mathematical algorithms and an encryption key to scramble data; instead, it replaces sensitive information with randomly generated tokens. This is an important distinction because encrypted strings can be decrypted by anyone who gains access to the encryption key. To learn more about these differences, check out our blog that compares tokenization and encryption.
Comparing Vaulted and Vaultless Tokenization
So, now that we’ve described the differences between tokenization and encryption, let’s return to the focus of this post: What are the differences between vaulted tokenization and vaultless tokenization?
Vaulted tokenization involves storing the mapping between sensitive data and tokens in a secure vault, as described above. In contrast, vaultless tokenization typically relies on encryption techniques to protect data, leaving the mapping between data and tokens unprotected if your encryption is cracked.
This distinction has significant implications for data security and compliance.
Why Vaultless Tokenization is Actually Encryption (and Isn’t PCI Compliant)
Vaultless tokenization solutions may appear similar to vaulted tokenization on the surface, but they lack the essential security and compliance features that vaulted tokenization offers.
Returning to our example above, if a malicious actor discovers that the token “d7-4c-5734” corresponds to “John Doe”, that doesn’t impact the security of other sensitive data if “John Doe” and other customer names like “Mary Joe” and “Abby Smith” are stored in a vault. With vaulted tokenization, there’s no relationship between the plaintext data and its obfuscated form.
On the other hand, with vaultless tokenization (which is a form of encryption), a malicious actor who discovers that “d7-4c-5734” corresponds to “John Doe” can now decrypt the names of other customers from their tokens.
This is the reason that the Payment Card Industry Data Security Standard (PCI DSS) doesn’t recognize vaultless tokenization as a secure method to protect PANs.
As they put it:
Note that where token generation is based on a reversible encryption method (where the token is mathematically derived from the original PAN through the use of an encryption algorithm and cryptographic key), the resultant token is an encrypted PAN, and may be subject to PCI DSS considerations in addition to those included in this document. The PCI SSC is further evaluating how these considerations may impact PCI DSS scope for reversible, encryption-based tokens.
Vaulted tokenization that’s PCI DSS compliant relies on a secure token vault to store the mapping between sensitive data and tokens, so that tokens generated by this method cannot be "decrypted" to reveal the original data.
Four Key Limitations of Vaultless Tokenization
Now that we've clarified the differences between vaulted and vaultless tokenization, let's explore the comparative limitations of vaultless tokenization in more detail.
Limitation #1: Vaultless Tokenization Doesn't Support Data Use
Vaultless tokenization typically lacks support for a variety of scenarios that vaulted tokenization supports, including privacy-preserving analytics and data visibility. The lack of support for privacy-preserving analytics prevents companies from deriving insights from sensitive data without potentially compromising its privacy.
On the other hand, storing tokens in a data privacy vault that supports API-based interactions and SQL queries makes it easy to search within sensitive datasets without decrypting sensitive data, which avoids exposing this data to potential misuse. This makes searching for a specific customer by name easy to do without breaking data privacy or expanding your compliance scope.
Limitation #2: Vaultless Tokenization Requires You to Build and Maintain a Privacy Platform
Vaultless tokenization is generally provided in the form of a tool that accepts sensitive data as inputs and generates a token as an output. So, if this data doesn’t go into a vault, where does it go? As mentioned above, it’s stored in the token, which is actually just a piece of sensitive data in encrypted form.
Because you’re using a tokenization tool, you have to build and maintain your own data privacy platform to manage tokenization processes, access controls, and data protection policies. This adds to the operational overhead of using vaultless tokenization and may result in significant ongoing costs.
This compares poorly to the approach of using vaulted tokenization with a data privacy vault that is continuously maintained and improved to provide a comprehensive, low-overhead platform that eases compliance with any data privacy law or industry standard (SOC2, California’s CPRA, EU’s GDPR, Brazil’s LDPD, etc.).
Limitation #3: Vaultless Tokenization Doesn’t Provide Data Governance or Address Data Sprawl
Vaultless tokenization solutions lack data governance features like fine-grained access control. That’s because, without a vault, you don’t have a single place to implement access control policies for sensitive data.
The lack of mechanisms for managing and controlling access to sensitive data, tracking data usage, or enforcing data retention policies leaves companies using this approach without visibility into where they are storing sensitive data.
This limitation leads to sensitive data sprawl because such tokens can’t be safely copied and stored across your infrastructure, apps, and systems. This compares poorly to using non-exploitable tokens that can’t be reverse-engineered and can safely be used to reference sensitive data stored in a vault.
Data sprawl makes it extremely challenging to maintain compliance with privacy regulations and complicates any attempt to respond to data subject requests (DSRs) under GDPR or similar laws like CPRA in a comprehensive (or cost-effective) manner. This is especially true for the most challenging type of DSRs: erasure requests (sometimes called “right to be forgotten” requests).
Here’s what happens when you receive an erasure DSR from a former customer:
- With vaultless tokenization, you need to find and delete each place where this data subject’s sensitive data is stored in tokenized form to fulfill the DSR. This means hunting through all of your apps and systems for these tokens. It can cost you thousands of dollars in labor, and worse yet, it’s error-prone because if you miss one token copy, you haven’t complied with the request.
- With vaulted tokenization, you only need to delete the data subject’s sensitive data from the vault – any tokens referring to that data subject now become meaningless. This can be fully automated and completed with one or two API calls.
Limitation #4: Vaultless Tokenization Doesn’t Simplify Data Residency
Global companies must navigate complex data residency requirements, which necessitate storing data (even in encrypted form) within specific geographic boundaries. Because vaultless tokenization creates “tokens” that are actually encrypted sensitive data, it doesn’t inherently support these requirements, making it difficult for organizations to expand into new markets while adhering to local data privacy laws, like the EU’s GDPR (just ask TikTok) or Brazil’s LGPD.
As shown below, vaultless tokenization forces you to replicate your architecture in each market that has data residency requirements:
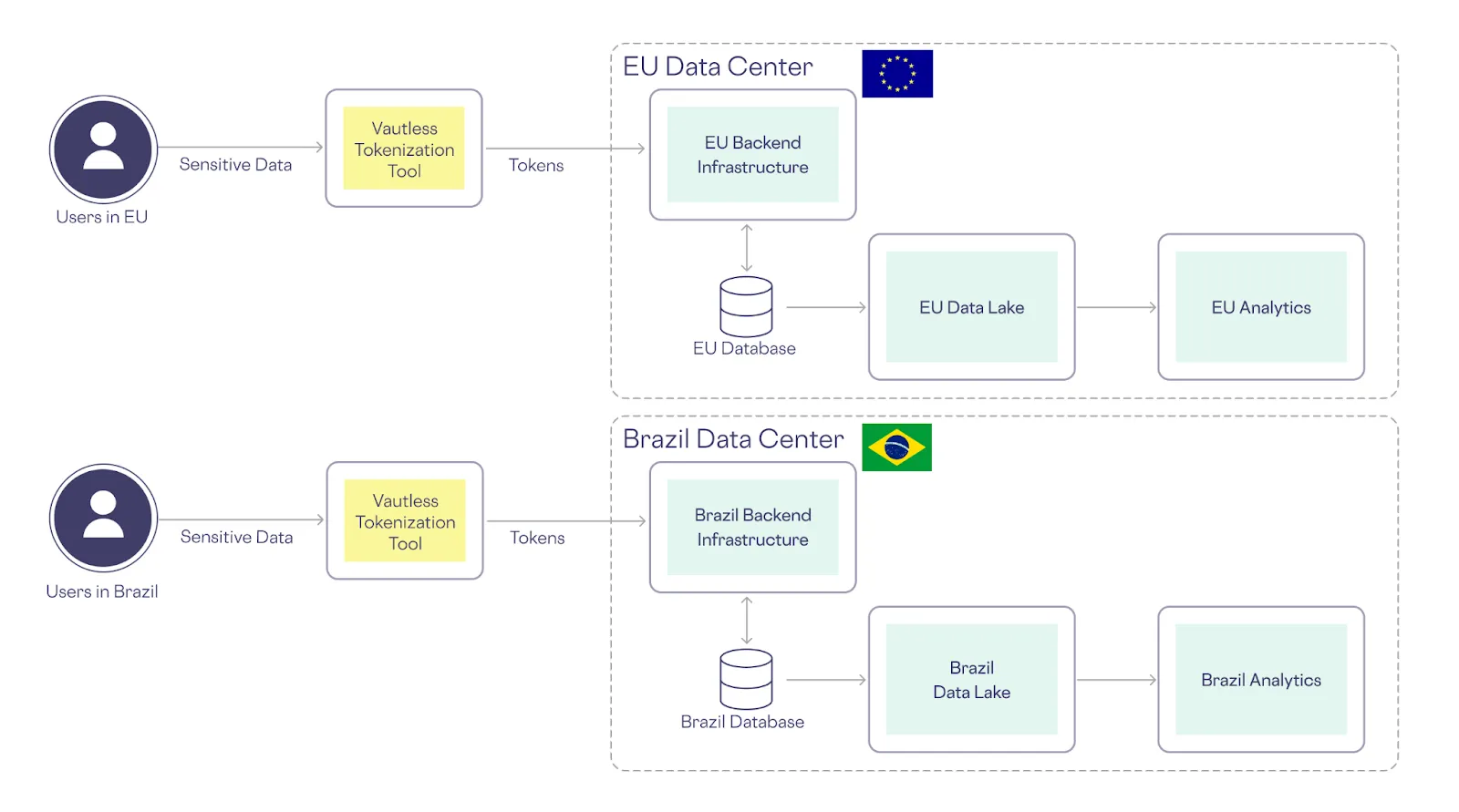
Data Residency with a Vault
On the other hand, with a data privacy vault that provides vaulted tokenization, you can place vaults in the regions that are closest to your customers while storing non-exploitable tokens in your centralized infrastructure.
A Closer Look at Vaulted Tokenization with Skyflow
In the preceding section, we discussed the limitations of vaultless tokenization, and how you can address them by using a comprehensive data privacy platform that features vaulted tokenization: Skyflow Data Privacy Vault.
The following table summarizes why Skyflow offers a better approach to tokenization:
Extensive Support for Sensitive Data Use
With Skyflow Data Privacy Vault, you can support the need for privacy-preserving analytics throughout your analytics pipeline.
Skyflow Data Privacy Vault lets you use sensitive data without compromising on data privacy with a set of SDKs and APIs, as well as support for SQL queries. This gives you access to sensitive data subject to strict zero trust controls that maintain the security of this data.
Skyflow also provides more than just tokenization. This is important because tokenization, like encryption, doesn’t support every use case. For example, let’s say that you want to run aggregate analytics on sensitive data to answer questions like the following:
- What is the average credit score of our customers?
- What is the average age of our customers?
Neither conventional encryption nor tokenization allows you to answer these questions without first decrypting or detokenizing the sensitive data of all of your customers. To store all of this data in plain text form compromises their data privacy, as it could be of interest to malicious actors.
Similarly, neither conventional encryption nor tokenization lets you easily check if a customer’s credit score is above a certain threshold while keeping that credit score safely encrypted.
With Skyflow Data Privacy Vault, you have a better option: polymorphic encryption, a unique approach to protecting sensitive data that lets you run operations like aggregate analytics or threshold checks on sensitive data – while keeping that data safely encrypted.
A Privacy Platform, not Just a Tokenization Tool
Unlike vaultless tokenization solutions, Skyflow Data Privacy Vault encompasses a broader set of privacy and security features. It combines tokenization with advanced data protection capabilities, making it a versatile solution for securing sensitive data across your organization and sharing sensitive data with trusted third party services while maintaining data governance so you can define access controls, track data usage, and enforce retention policies.
A Fully-maintained and Extensible Platform
Skyflow is designed to minimize the operational burden on your organization. It offers a fully-maintained platform that reduces the need for extensive customization and ongoing maintenance. This allows your teams to focus on strategic initiatives rather than managing complex privacy infrastructure. This also means that you have built-in support for new and emerging technologies, so you can use LLMs without compromising on data privacy.
Data Governance to Prevent and Address Data Sprawl
With comprehensive data governance features and support for multiple types of non-exploitable tokens, Skyflow Data Privacy Vault helps organizations prevent and address data sprawl and maintain a clear understanding of where sensitive data resides within their ecosystem. This capability is crucial for complying with privacy regulations like the GDPR and CPRA.
Support for Scalable Data Residency
Skyflow gives you a better option than geo-replicating your entire architecture in each market that has data residency requirements.
Because vaulted tokens aren’t exploitable, they can be safely stored outside of the EU or Brazil without compromising the personal data of EU or Brazilian residents (which remains safely within those jurisdictions).
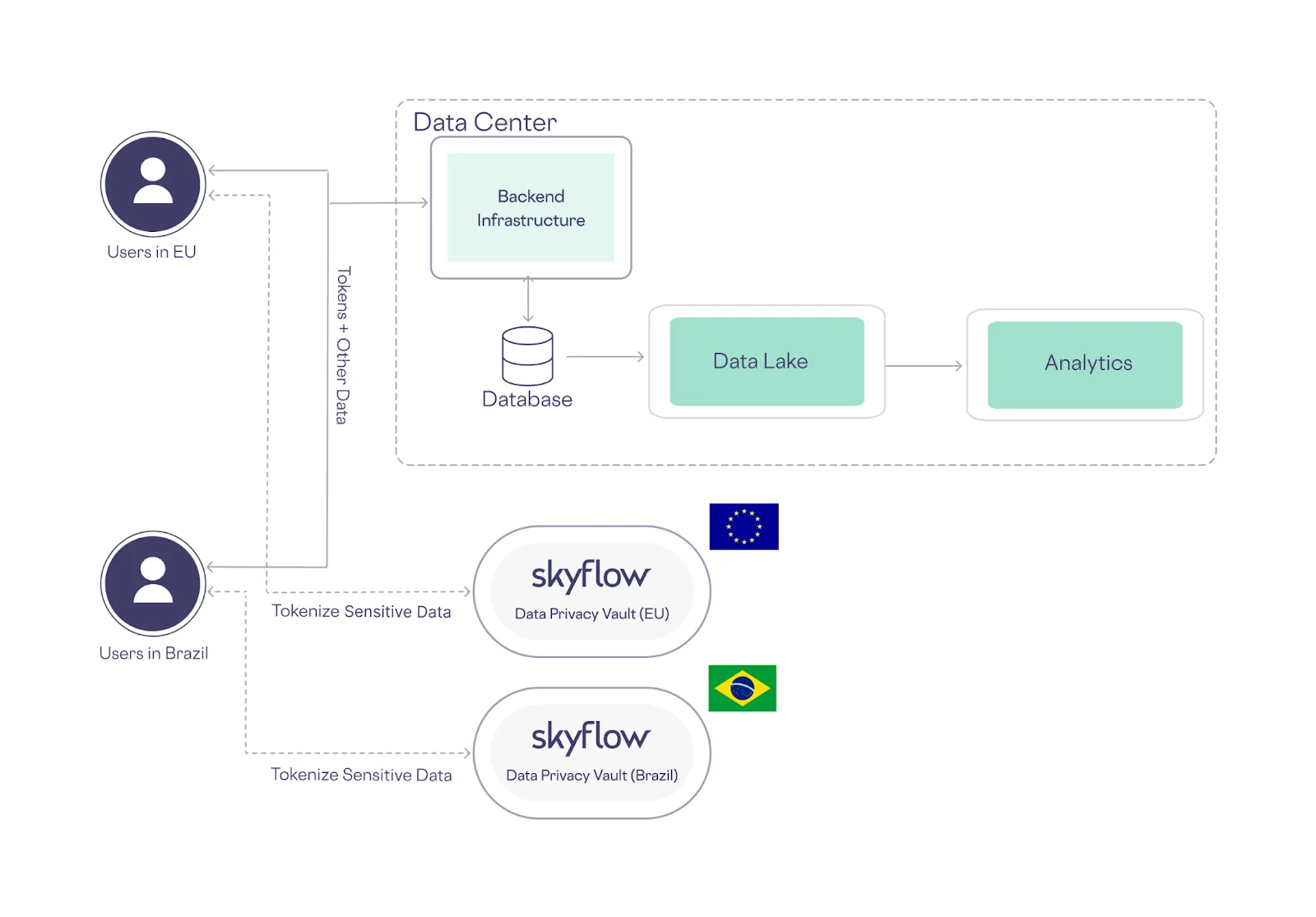
This approach not only eases compliance, it also reduces your cloud infrastructure costs and your maintenance-related labor costs.
To learn more about how tokenization with a data privacy vault supports data residency, check out our data residency blog post.
How Skyflow Makes Migration from Vaulted Tokenization Easy
Skyflow makes migration from other tokenization solutions to vaulted tokenization with Skyflow Data Privacy vault easy and seamless by leveraging our bring-your-own-token (BYOT) capability and the experience of our team of data migration experts.
BYOT Allows Migration to a Vault At Scale
Skyflow has developed a unique approach to migration that’s based on our BYOT capability. This feature enables a smooth transition from vaultless tokenization to Skyflow Data Privacy Vault without disrupting your business operations.
With BYOT, you can retain your existing tokens generated with a legacy tokenization system and seamlessly integrate them into Skyflow Data Privacy Vault. The tokens you've already generated and used in your systems can be migrated into Skyflow with zero downtime using a variety of methods, including bulk inserts to Skyflow APIs with a tokenization proxy, as shown below:
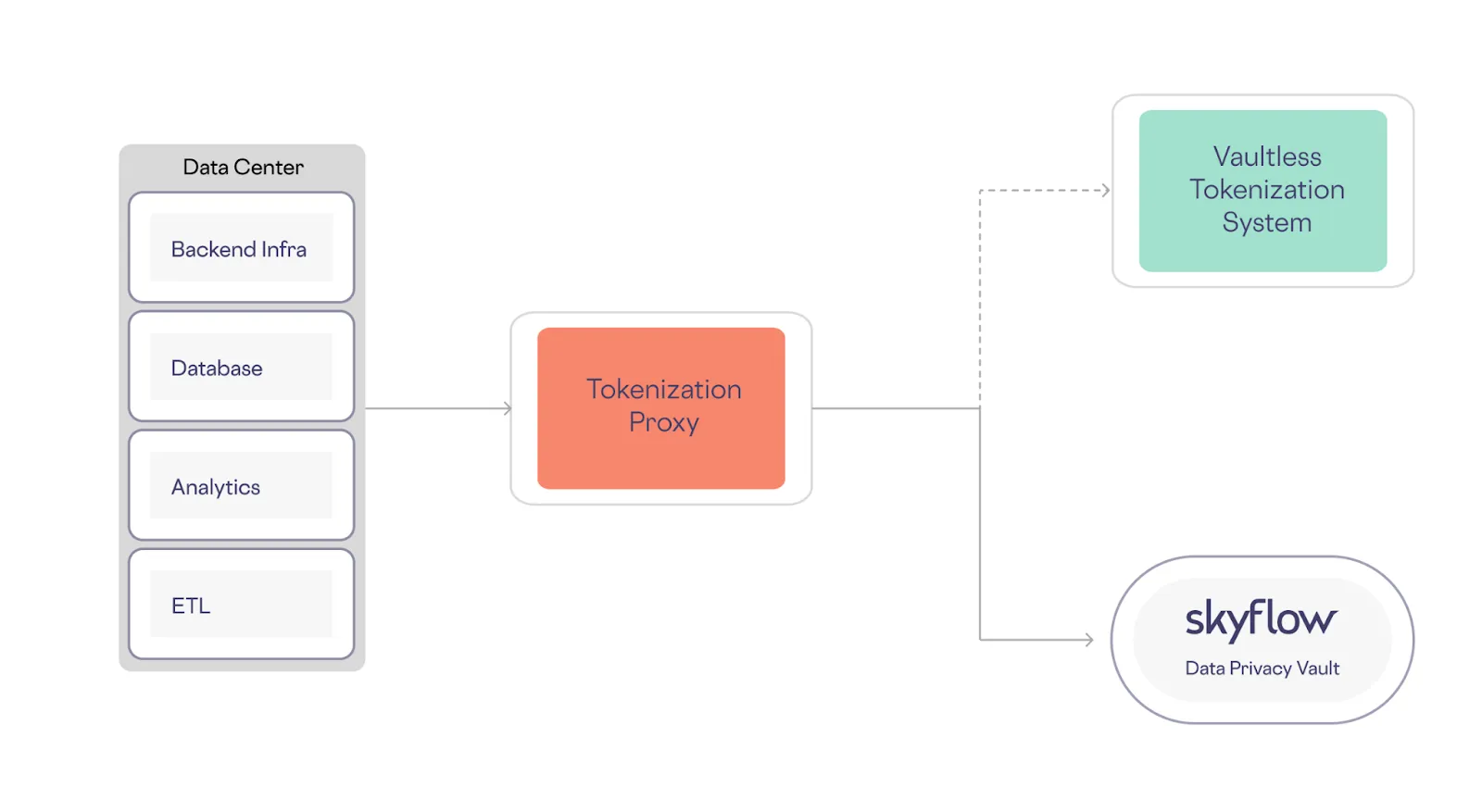
During the migration period, new and existing tokens are migrated to Skyflow along with plaintext data values. After the migration, you can use tokens generated by Skyflow, and gradually phase out legacy tokens that existed before the migration.
Our platform's flexibility allows you to start small and expand gradually, ensuring a smooth transition that aligns with your organization's pace and priorities. You can migrate data incrementally, test the new setup, and gradually shift workloads as you gain confidence in the migration process.
Skyflow Can Provide Seamless Migrations from Vaultless Tokenization
Our team of experts has a wealth of experience in assisting organizations with the migration from vaultless tokenization to Skyflow Data Privacy Vault – while keeping their sensitive data secure and private throughout the process.
We recently migrated a company that was using vaultless tokenization for over 700 million records to their Skyflow Data Privacy Vault – with zero downtime.
Final Thoughts
Your business needs a modern data privacy platform that goes beyond vaultless tokenization and provides comprehensive data protection and governance capabilities. Skyflow Data Privacy Vault offers the solution you need to secure your sensitive data effectively. And, we have the features and experience you need to successfully and painlessly migrate your data away from vaultless tokenization.