
The Limitations of Traditional Tokenization
Most traditional tokenization systems fail to account for input data types during token generation, severely limiting support for analytics. Also, the lack of context around sensitive data inputs prevents most tokenization systems from securely managing the detokenization process. Skyflow brings tokenization, encryption, and policy-based governance together to address the limitations of traditional tokenization.
Tokenization is the process of substituting sensitive data elements like customer names for non-sensitive tokens. One of the most common forms of tokenization is PCI tokenization (or vault tokenization), which exchanges credit card data for randomly generated tokens. These tokens can be safely stored within your application’s backend systems without adding those systems to your PCI compliance scope.
You can use tokenization to de-identify a wide variety of sensitive PII data types – such as people’s names, addresses, social security numbers, and dates of birth. Tokenization is also useful for storing healthcare data (PHI), or other types of sensitive data such as unreleased quarterly financial results.
Detokenization is the inverse of the tokenization process, where tokens are used to retrieve original plaintext values.
Traditional tokenization systems manage both tokenization and detokenization through a token map, similar to a hashtable, that connects each unique token to the original value. Doing this can help reduce your compliance scope, however, there are several limitations that impact data usage and security.
The Limitations of Traditional Tokenization Systems
There are three major limitations of traditional tokenization systems.
- Token Overload: Mapping a given string to a given token for analytics purposes can cause issues with data subject requests, including right to be forgotten (RTBF) requests
- Limited Security Model for Detokenization: Traditionally, a user or process has permissions to redeem any token, or no tokens – you'd need more granular access controls to improve security
- Choice Between Tokenization and Encryption: Traditional tokenization systems generally don’t integrate encryption, which limits the security they can provide compared with a more integrated approach
Token Overload: The ‘Austin Problem’
To support search look up and analytics use cases using only tokens, it’s important that the same input value generates the same token value. To support such use cases, a tokenization system can generate deterministic tokens (sometimes called consistent tokens).
With a deterministic (or consistent) tokenization method, the same country or zip code will always generate the same token value (as shown below) even though there’s no mathematical relationship between the generated token and the original value.
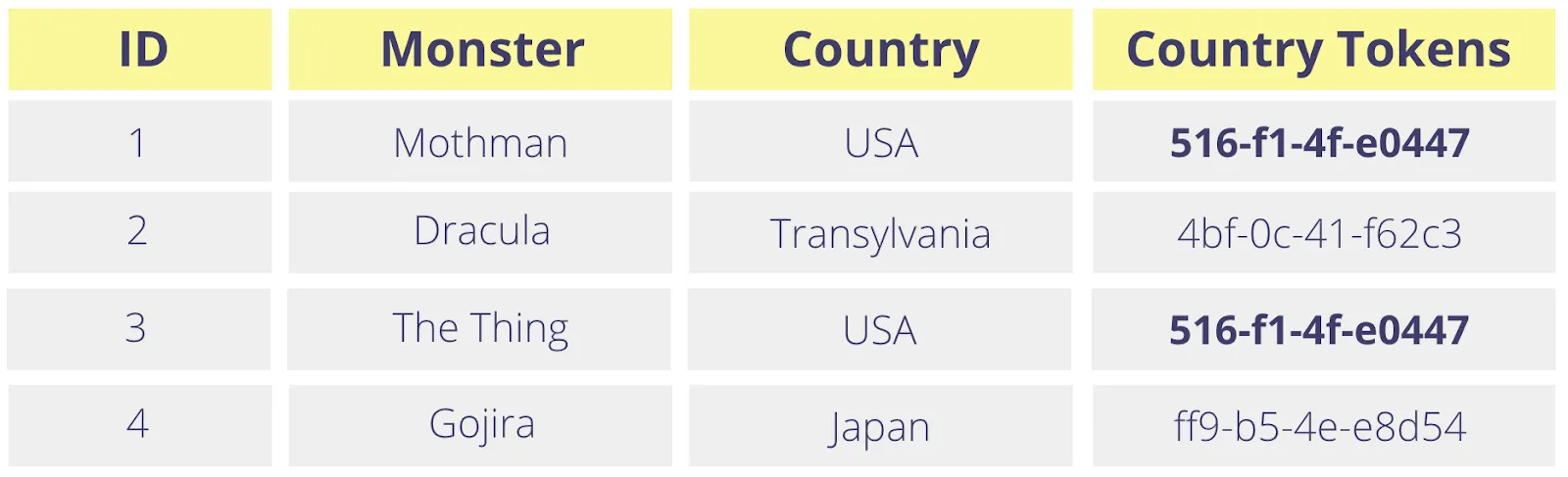
With a deterministic token, you can perform joins across tables, and also run group by and count operations just as you would against the original values. However, since the token map has no contextual information about the input, this naive approach can lead to undesirable effects. This is especially true when the same string refers to two very different real-world entities.
For example, if the first name of a customer is 'Austin' and another customer also lives in the city of Austin, Texas, then the name, 'Austin' and the city, 'Austin' will generate the same token value. Depending on the structure of your analytics store, this could lead to incorrect calculations during query processing if you’re relying on tokens in your data warehouse.
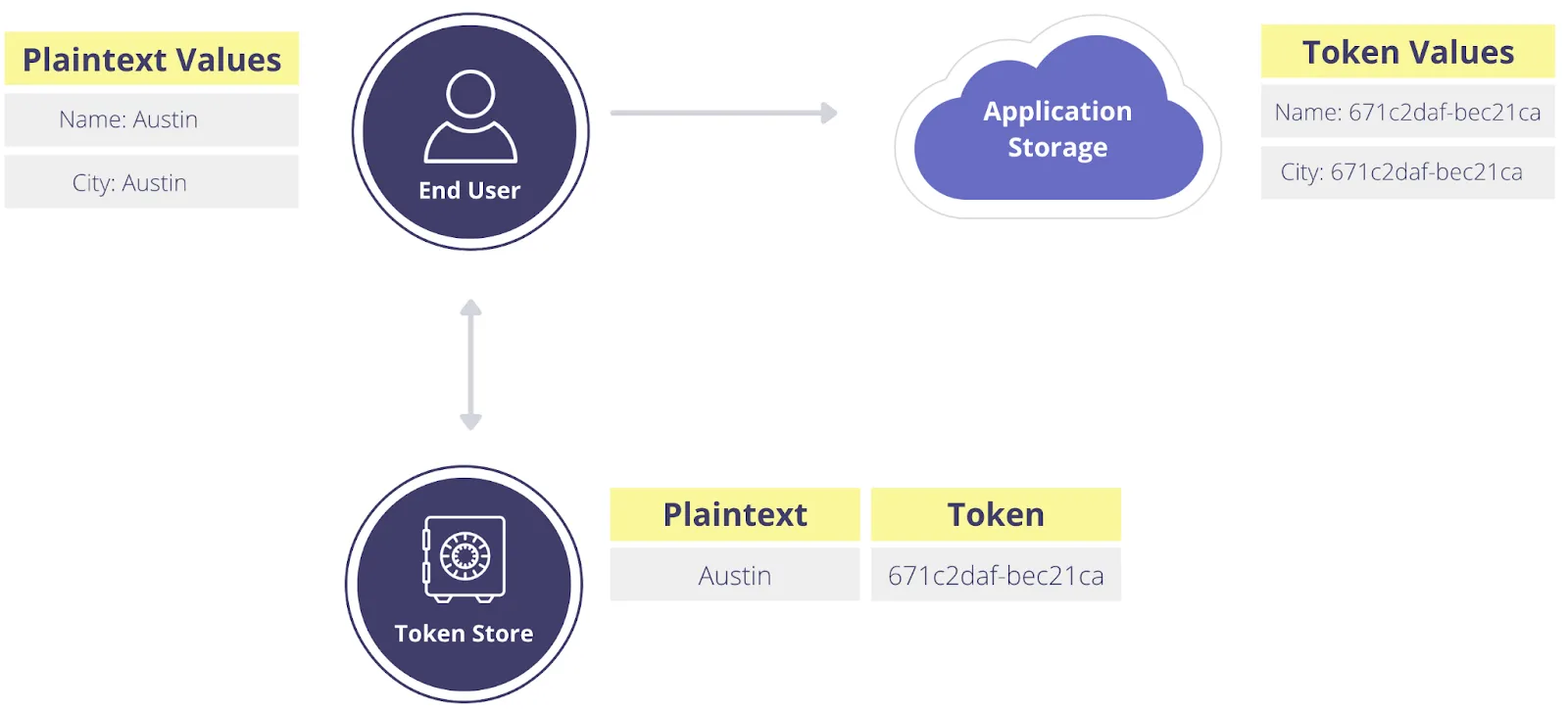
Token Overload Complicates Right to be Forgotten Requests
Token overload is caused by a common issue in programming: data that’s insufficiently typed. And this problem becomes much more troublesome when it’s combined with the need to comply with data subject requests that are a feature of many data privacy laws like GDPR and CCPA. And while it could cause some headaches when compiling a data subject request for all personal data on an individual, that pales in comparison to what happens when you have overloaded tokens and you need to comply with a right to be forgotten (RTBF) request.
If you only have one customer with the name 'Austin', you’d ideally want to delete the mapping from 'Austin' to the token value in the Token Store, invalidating any tokens you have stored in your downstream services. This isn’t possible if you need to keep the token mapping for your customers that live in the city of Austin, Texas. So, what could have been a quick and easy compliance step turns into a manual project if you want to avoid breaking your analytics for customers in that city.
On the other hand, RTBF compliance is easy if your tokenization scheme is deterministic and yet data type aware – so Austin, Texas and 'Austin' (the person filing an RTBF) each have a unique token that’s deterministic across references in your database.
Limited Security Model for Detokenization
Another major limitation of the traditional tokenization approach is that users and services are either authorized to detokenize data, or they’re not. This means if you have the right to detokenize, you can detokenize any token, even if that token doesn’t belong to you.
Ideally, not only should detokenization be restricted to a subset of data based on what’s needed by a user or service, but the detokenized value should be use case specific.
For example, a marketer detokenizing a customer’s date of birth should only need to know the day and month so they can send the customer a birthday email. They don’t need to know the customer’s exact age. However, the owner of that data (the customer) should be able to see their full date of birth to verify it’s correct and fix any mistakes.
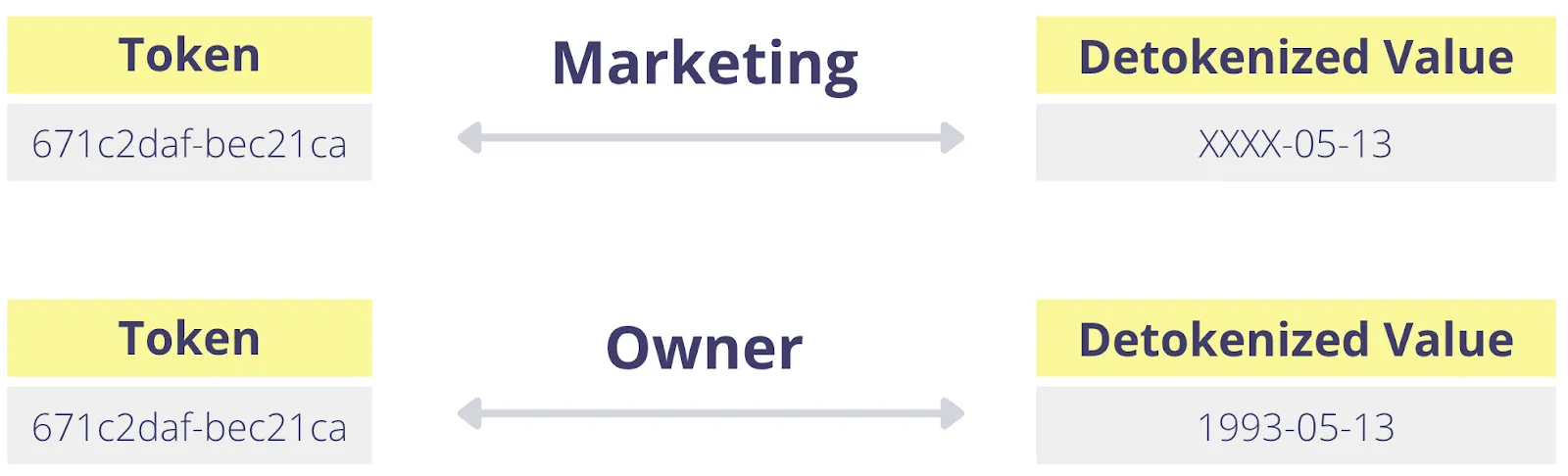
This gets even more complicated when considering that sensitive data should have different levels of visibility, not just based on use case but also depending on the data type.
Returning to the ‘Austin Problem’, there are use cases where a user of a system should be able to view someone’s first name in plaintext but not view their home city. This security model is impossible to support in traditional tokenization systems since there’s no distinction made between the name of a person versus a city. It’s the classic computing problem of data not being typed or mapped to a schema, cropping up again in the context of tokenization.
Choice Between Tokenization and Encryption
With standard tokenization approaches, data encryption is a separate system. Detokenization brings the data back in plaintext. If masking is required, it’s applied in real time against the plaintext values. Because encryption, detokenization, and masking aren’t integrated in traditional tokenization systems, each of these integration points presents potential vulnerabilities.
Tokenization has the advantage that there’s no mathematical connection between the original value and the token, whereas with encryption, the process can be reverse engineered. Tokens are also easier to search across and use for analytics, while encrypted data needs to be decrypted to support its use. Still, developers often find themselves wishing that it was easier to combine tokenization and encryption.
Tokenization, Access Control, and Encryption Working Together
Skyflow Data Privacy Vault provides solutions to these problems with a schema-based tokenization system: one that knows the data type of the input. Some traditional tokenization systems have support for predefined data types, but with Skyflow, you have the flexibility to create and support any custom data type.
Each column within the schema can define its own custom format rules, allowing you to generate any kind of token. In the example image below, you can see the settings for a format-preserving deterministic token for a credit card number, and also a UUID deterministic token for a cardholder name.
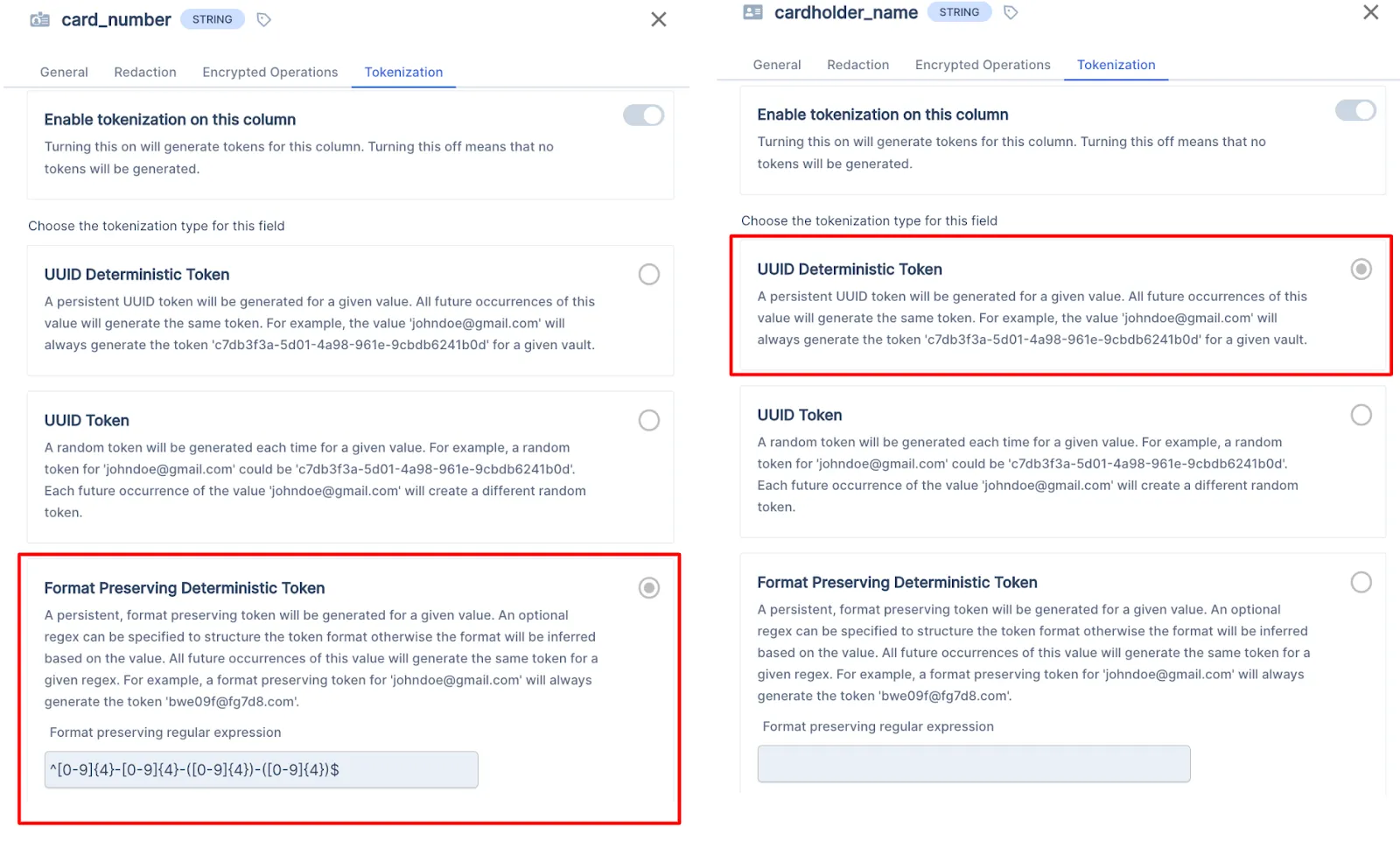
For example, the token for a social security number can still look like a social security number or the token for an email can still look like an email.
Solving The ‘Austin Problem’
When defining the schema for a vault, the tokenization scheme can be set on a per column basis. There are a number of tokenization schemes supported, including deterministic tokens. However, depending on how these are configured, you can still end up suffering from token overload – the ‘Austin Problem’ described above.
As a solution to this problem, you can use Skyflow’s column group feature to define the boundaries within which your deterministic tokens span. So instead of a deterministic tokenization method being vault-wide across all inputs, you can restrict it to a subset of columns – a column group. Column groups are similar to the programming principle of namespaces.
For example, consider the following set of sample data stored in a vault’s Customers table:
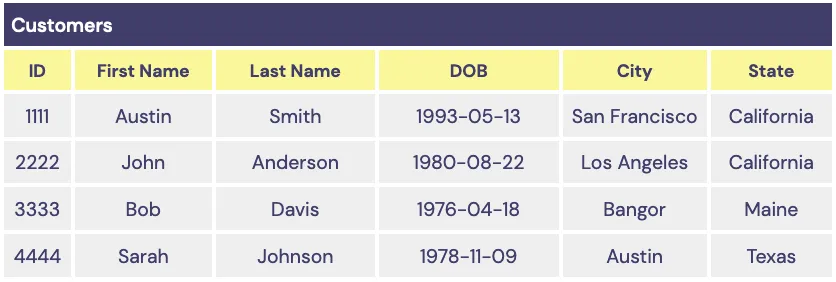
Without column groups, if both First Name and City are set to tokenize with deterministic UUIDs, then both the First Name for customer 1111 and the City for customer 4444 will generate the same UUID.
To avoid this, you can create a column group that consists of the First Name and Last Name columns. Inputs from these two columns will have deterministic tokenization within their column group, but values outside of this column group will have a different set of deterministic tokens. This means two First Name values of 'Austin' will still generate the same UUID, but the City of 'Austin' will result in a different UUID.
A Greatly Improved Security Model
Skyflow supports a powerful data governance engine with policies that give you fine-grained control over access to the columns and rows of data stored within your vault, all based around a zero trust model. These policies let you control not only what data can be viewed, but also how that data can be viewed – redacted, partially redacted, or in plaintext.
With support for column group tokenization, Skyflow’s fine-grained policy-based access control now extends to the detokenization process. This means you can control exactly which columns and rows a user or service can detokenize and how the resulting data is formatted.
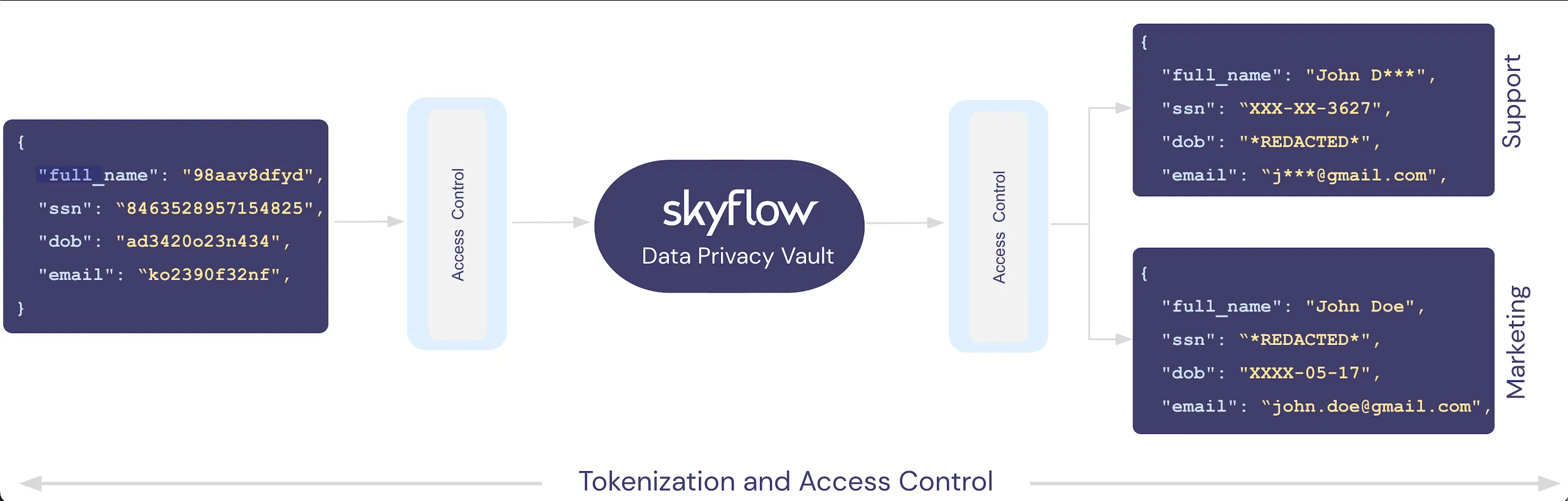
For example, in the customer PII data vault shown above, you can create a policy for your customer support agents in California that limits their access to only the rows where customers have a matching state of California. Additionally, you can set the detokenization rules so that the agent only sees the DOB data as a partially redacted value that reveals the day and month of birth, while hiding the year of birth. Finally, with polymorphic encryption, this full date of birth is never available to the agent – in fact, it isn’t even present in their frontend app’s memory.
Limiting the Scale of an Attack
In the standard tokenization model, if a malicious actor were to capture all your customer tokens and an API key for detokenization, they’d be able to see all your customer data. With policy-based detokenization, even if someone managed to capture all your customer tokens and someone’s API key, the amount of data they could detokenize would be severely limited. When combined with features like time-to-live fields, this drastically reduces the potential scale of a breach. To learn more about this use case, see Dynamic Access Control of Sensitive User Data.
Wrapping Up
With Skyflow Data Privacy Vault, tokenization, access control, and encryption work together. And with polymorphic encryption, data is never decrypted unless you explicitly give someone the right to view that data in plaintext.
This means that if a user can detokenize data as a masked value, only the masked value is available, and all other parts of the field are encrypted and redacted. Policy-based access control based around a zero trust framework gives you fine-grained control over who can see what, and how they see it.
This combination of features lets you overcome the security challenges and limitations of a traditional tokenization framework. It provides solutions to the gaps left by simplistic, limited security models without restricting your ability to fully utilize sensitive customer data.
You can read more about how a data privacy vault makes it easy to protect the privacy of customer data in this white paper.