
What Is a Data Subject Request?
A data subject request is a legal concept first introduced by the EU’s GDPR that allows individuals to query, delete, or update their sensitive personal data that’s held by businesses. Such requests can be expensive for businesses unless they use a data privacy vault to isolate, protect, and govern this data.
Data subject requests (DSRs) were first introduced with the passage of the General Data Protection Regulation (GDPR) in the EU in 2016. Under GDPR, all “data subjects” have certain rights, including the right to access, erase, or correct their data under a DSR process. DSRs are also present in the California Privacy Rights Act (CPRA), which amends the California Consumer Privacy Act (CCPA). As more and more countries pass laws similar to GDPR, more companies will need to plan how they will handle DSRs.
In this post, we’ll explore the topic of DSRs and the challenges faced by businesses that suffer from sensitive data sprawl when responding to DSRs. Finally, we’ll look at how using Skyflow Data Privacy Vault to isolate sensitive personal data eases compliance with DSR requirements.
Data Subjects and Their Right to DSRs
Before discussing DSRs in-depth, it’s important to understand the idea of a “data subject”. GDPR and CPRA both define a data subject in terms of how closely data can be tied to an individual person.
Here’s what GDPR has to say on the topic:
“‘Personal data’ means any information relating to an identified or identifiable natural person (‘data subject’)” - GDPR Article 4.1
In other words, a data subject is anyone who has data that can be directly tied to them collected by one or more companies. A data subject has certain rights that vary from one law to another, but that generally include the right to access, correct, or delete their personal data.
Put simply, a DSR is when someone invokes their rights under these laws by asking a company or other entity to report on, alter, or delete their personal data.
Types of DSRs under GDPR and CPRA
Both GDPR and CPRA are similar in the requirements that they define for DSRs, but there are some key differences.
The most common types of DSRs under GDPR include the following:
- Article 15 – Right of access by the data subject: This allows data subjects to learn whether or not their data is being collected and get a copy of that data. Such requests are often referred to as data subject access requests, or DSARs (which are a type of DSR).
- Article 16 – Right to rectification: This grants data subjects the right to request that any inaccurate or erroneous data be corrected.
- Article 17 – Right to erasure: More commonly known as ‘the right to be forgotten’, this allows a data subject to request that any personal data related to them be deleted.
California’s CCPA, as amended by CPRA, allows data subjects to file the same types of DSRs. And, both CCPA and GDPR impose fines or other penalties for not deleting personal data if a company doesn’t comply with “right to be forgotten” requests.
One crucial difference is that GDPR requires that data subjects ‘opt-in’ (or consent to their data being collected and processed), while CCPA and CPRA put the onus on the data subject to ‘opt-out’ of data collection and processing.
So, how can companies manage such requests, and what challenges do they face?
Data Subject Requests: A Continuous Challenge
If you’re familiar with how data flows between systems and applications in most system architectures, you can appreciate that complying with DSRs presents major challenges to many companies.
This is especially true for companies that suffer from sensitive data sprawl. Sensitive data sprawl occurs when sensitive data is replicated as it’s copied and stored across various applications, databases, data pipelines, and logs. Data sprawl is further complicated by the use of “write once only media” (sometimes known as “WORM”), machine learning models, and generative AI large language models – none of which provide straightforward support for deleting specific pieces of sensitive data like a name or social security number.
Data sprawl makes it exceedingly difficult to effectively govern access to sensitive data and increases the work required to comply with data privacy laws and industry standards like PCI.
When you start investigating the extent of sensitive data sprawl in your systems, you’ll probably discover that sensitive data is present nearly everywhere. Copies of various types of sensitive data end up scattered across your systems and applications, as shown below:
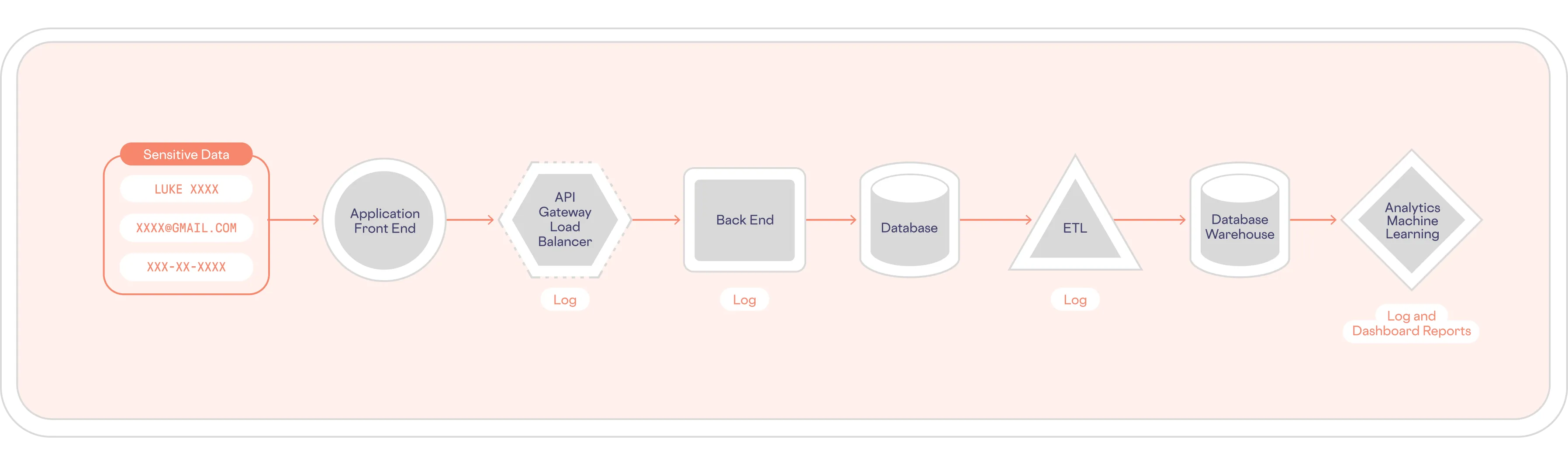
To comply with a “right to be forgotten” DSR, you need to find and delete all copies of the subject’s personal data, including copies that have been replicated into your database, ETL, analytics, etc. – not to mention the logs created by each of these systems.
With data sprawl, you lack sensitive data visibility. This means that processing DSRs can be far from straightforward. With an architecture like the one shown above, you would need to query six or more individual systems to find a data subject’s personal information, not including any copies of this data found in log files. Even in a relatively simple architecture, you will likely need dozens of queries to find all copies of a subject’s personal data.
For example, finding all the data required for a DSR could require you to run a variety of queries against several SQL and NoSQL databases, logs, and ETL pipelines. And, if some of this sensitive data is present in a Large Language Model (LLM)-based AI tool like a chatbot, you might find that you have no way to delete it.
And even then, can you be certain that you’ve found all copies of the data subject’s personal data? What if some departments are using tools that aren’t approved by IT, and personal data is present in those systems? With a traditional data architecture, you can end up spending a lot of time on a DSR without being 100% confident that you’ve found every copy of the subject’s personal data.
To simplify DSRs, you need to address the problem of data sprawl by isolating personal data in a data privacy vault.
Easily Manage DSRs with Skyflow
A data privacy vault isolates, protects, and governs access to sensitive personal data so that employees and workflows get access to only the data that they need, and nothing more. And, a data privacy vault gives you a centralized place to turn your data governance guidelines into effective, maintainable access control policies that go beyond what’s available in a data warehouse or database. Each system that previously contained plaintext personal data instead contains non-exploitable tokens that point to records in the vault.
Skyflow Data Privacy Vault lets you solve the problem of data sprawl, updating the architecture shown above to one where sensitive data is isolated, protected, and governed in a vault, as shown below:
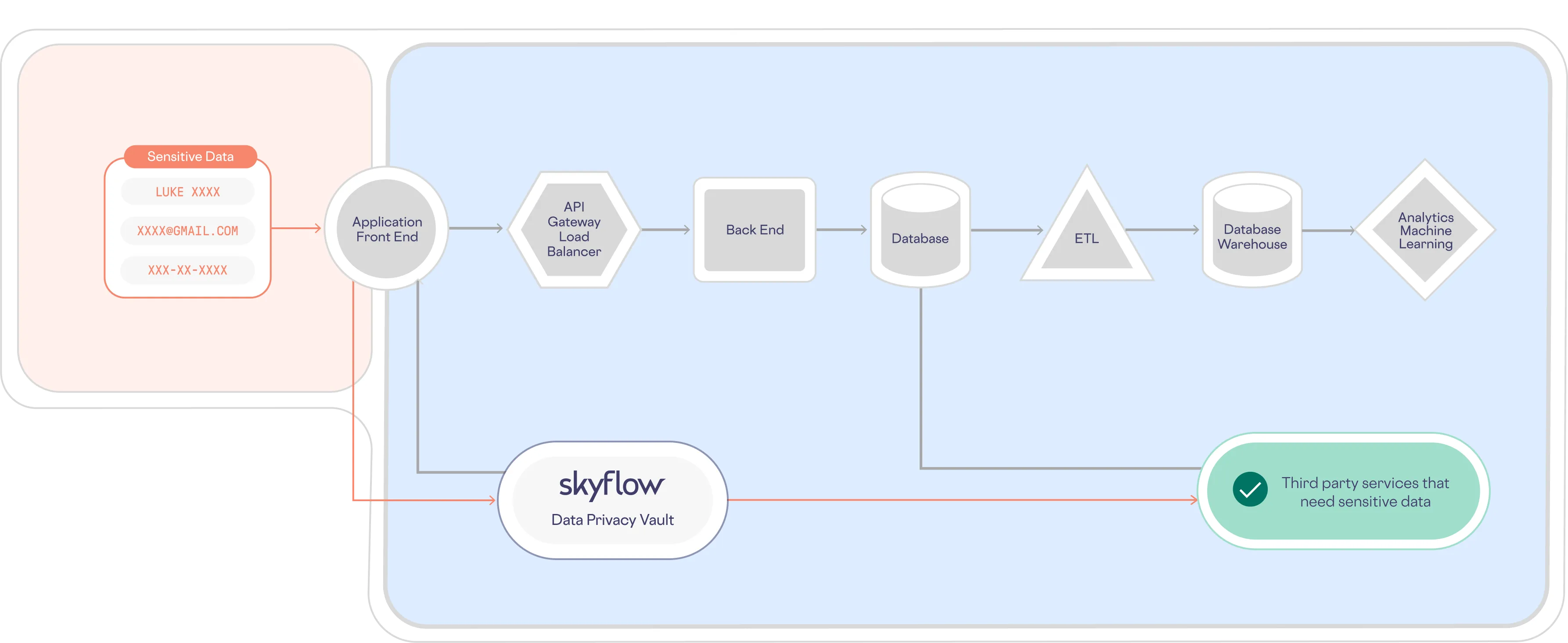
Because all personal data for a given data subject is isolated in the vault, that’s the only place you need to run queries (or make updates) when handling a DSR.
So, how can you make sure that you locate all of the data stored in Skyflow for a given data subject? By associating all of that data with a unique identifier you can define when setting up your schema: subject_id.
For example, let’s say that a customer sends you a request to delete their records. After querying Skyflow to determine this customer’s subject_id, you can then use that ID to quickly locate all of their records.
Here’s an example of how you would query to find the subject_id of a user named ‘Alex Luther’:
With this user’s subject_id, you can easily find records associated with this data subject by querying your vault.
Improving DSRs with Substring Matching
Of course, even with queries built using the data subject’s subject_id,you won’t find all of a subject’s personal information if their name or other personal data is contained within larger text fields that aren’t associated with this subject_id.
But, Skyflow has a solution for that: Skyflow queries support substring matching to find personal information within longer string fields using SQL LIKE and ILIKE operators.
So, let’s say that we need to query within some longer string fields stored in Skyflow for records containing the name ‘Alex Luther’. You could do this with a query like the following:
You can even use substring matching to comply with DSRs from individuals who have changed their name or might have used multiple names. For example, let’s say that you wanted to query for the string “Lex Luther” because “Alex Luther” has used this nickname in some contexts. You could do this with the following query:
Try Skyflow for DSRs
With Skyflow, you can isolate, protect, and govern sensitive data and avoid data sprawl. You can also use features like user data aggregation by subject_id to conduct comprehensive searches for personal information without querying multiple data sources – or sacrificing data privacy. These features reduce the cost and complexity of processing DSRs to comply with laws like GDPR and CPRA.
To learn more about how Skyflow can help you protect sensitive data without sacrificing data use, contact us.