Maximize Privacy while Preserving Utility for Data Analytics
Privacy-aware analytics is a challenge for many companies. Sensitive customer data tends to find its way into our analytics pipelines, ending up in our data warehouses and metrics dashboards. In this post, we show through specific use cases how you can reduce compliance scope and improve your privacy posture while still computing analytics important to your business.
It often seems like you need sensitive customer data in your data warehouse to compute the metrics most important to your business. For example, you might want to know the efficacy of a clinical trial based on different participant cohorts, spending habits of your customers, customer behavior by geography, shopping preference by credit card issuer – just to name a few. However, replicating customer PII to your downstream services greatly increases your compliance scope and makes maintaining data privacy and security significantly more challenging.
To address this problem, you can use a data privacy vault that features privacy-preserving technologies like tokenization and polymorphic encryption to maximize the utility of your data analytics pipeline while preserving privacy and reducing compliance scope.
How to De-identify Data in an Analytics Pipeline
Analytics pipelines typically aggregate data from multiple sources through a combination of batch and stream processing technologies to a downstream storage system like a data warehouse. Business intelligence (BI) tools integrate directly with the warehouse to help deliver insights for the business.
However, when sensitive customer data ends up in your analytics pipeline, it becomes available to anyone running analytics within your organization. This increases the potential attack surface for a data breach and also causes compliance headaches. One solution to this problem is to de-identify sensitive data by replacing this data with non-sensitive tokens. These tokens end up in your warehouse and other downstream services rather than the sensitive data.
In prior blog posts, we’ve shown how you can de-identify analytics data by using Skyflow Data Privacy Vault with AWS, or with Snowflake. Regardless of the underlying technologies used, the overall process is similar. You want to de-identify sensitive data as early in the lifecycle as possible. You also need to perform intelligent transformations on this data when needed to make sure you can support various analytics workflows.
As shown below, it’s common to process multiple data sources through both batch and real-time ingestion processes:
- PII Detection: First, PII is detected and sent directly to the data privacy vault
- PII Tokenization: The vault replaces each sensitive data value with a token, and securely stores the original value
- Tokens Stored in Data Warehouse: Tokens are sent, along with other non-sensitive data, to the data warehouse
- PII-Free Analytics and Reporting: Analytics and reporting applications use data from the warehouse as normal, providing data-driven insights for your business
In the next section, we’ll look at a specific schema and a set of use cases to see how you can use a data privacy vault in your analytics pipeline to answer important questions without relying on raw, plaintext PII values.
Maintaining Customer Privacy through Privacy-Safe Analytics
To see how you can preserve high data utility while using a data privacy vault to de-scope your analytics pipeline from compliance and data security concerns, let’s take a look at a specific example. Imagine that you manage a few types of sensitive customer data that you store in a Customers table, as follows:

Let’s also imagine that you have a separate table to track transactions by your customers, keying off the ID column in the Customers table:
A manager at your company would likely need to answer questions like:
- What are the spending habits of my customers?
- Are there meaningful differences in spending based on a customer’s location?
- Is shopping preference impacted by age?
- Are there different spending habits depending on the credit card issuer?
In this section, we’ll take a look at each of these questions and see how using a data privacy vault to thoughtfully de-identify data lets us answer them while preserving customer data privacy.
Question 1: “What are the spending habits of my customers”?
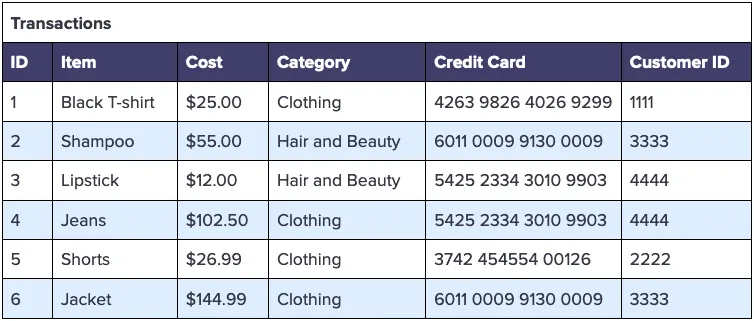
Spending habits could mean a variety of things, but let’s assume you need to know total spending across all customers by shopping category. You can easily accomplish this using just the cost and category values from the Transactions table found in your data warehouse. Your analysis might look like the following:
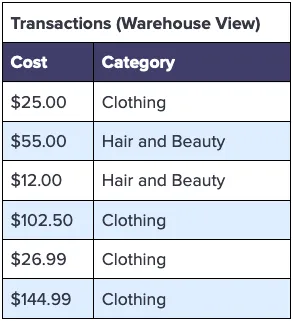
To support this analysis, you could drop the sensitive columns when processing these tables through the ingestion pipeline so you don’t store any PII within your data warehouse. Specifically, you could remove the following columns:
- The Name, Address, and DOB columns from the Customers table
- The Credit Card column from the Transactions table
Using de-identified data with these columns removed, an analyst can compute the total spend by category with a simple group by SQL statement, as follows:
In this case, the privacy-safe transformation is very simple: drop every sensitive column from the Customers and Transactions tables. Let’s take a look at a slightly more complex use case.
In this case, the privacy-safe transformation is very simple: drop every sensitive column from the Customers and Transactions tables. Let’s take a look at a slightly more complex use case.
Question 2: “Is there a meaningful difference in spending habits based on customer location”?
In this situation, you need to compute spending habits by customer location to see if location impacts spending. You can use the zip code within the address field as a representation of customer location. However, zip codes are a type of PII, so you don’t want to use actual zip code values if you can avoid it.
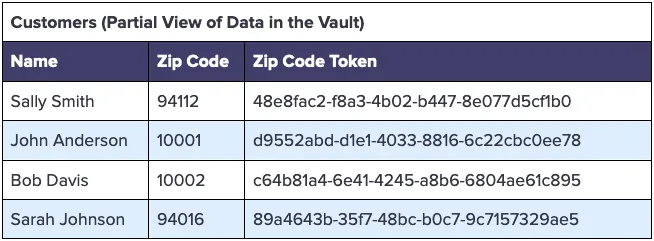
Instead of the plaintext zip code, you can use a consistent token for the zip code. With a consistent token, the same zip code for two independent customers will result in the same token value. Because the tokens are consistent, we can then group by the token value to determine if spending habits are impacted by geolocation. You would just need to update your Customers table to have a separate Zip Code column, distinct from the Address column.
Using this approach the data privacy vault becomes the single source of truth for sensitive customer data, and also maintains the token mapping, as follows:
The transformed warehouse Transactions table would then look something like the following, where the zip code has been substituted for a consistent token:
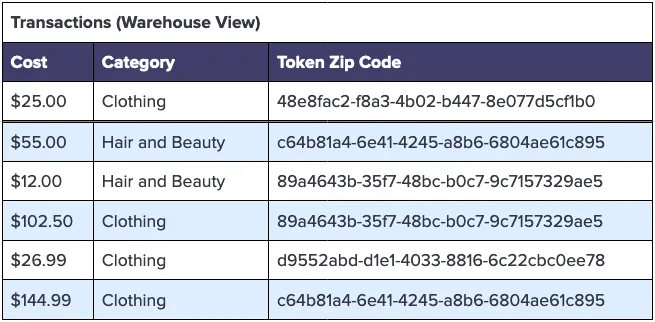
Using the data warehouse above, you can create the following visual representation of spending by geolocation. Without exposing any PII, you can verify the statistical significance of spending differences by customer location, as follows:
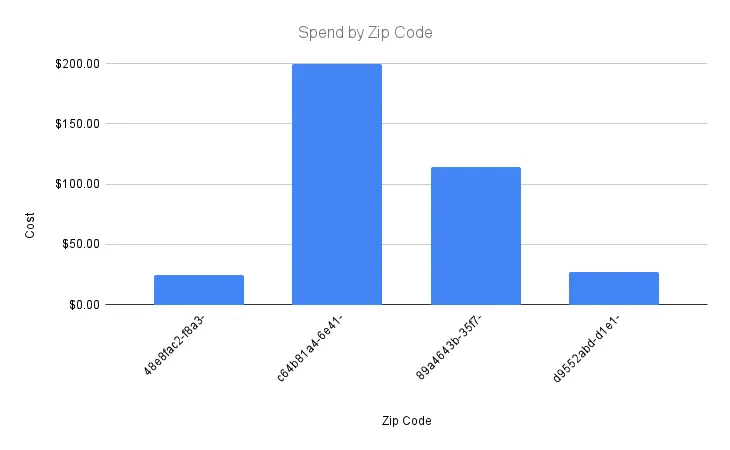
In some cases, you might need to re-identify these zip codes to add context to your aggregate analytics. For example, you might need to know which location is responsible for the most spending, or the least spending, to inform marketing efforts. To do this, you can detokenize the zip code token to retrieve the original value. Using tokens in this way gives you selective sensitive data access when you need it to interpret analytics, while keeping sensitive data out of your data warehouse.
Because all of the data is aggregated and the detokenization operation can be limited to a small set of privileged users, the risk of exposing sensitive data by detokenizing a few values to interpret analytics is low. It’s especially low in comparison to storing raw PII in your data warehouse.
Question 3: “Is shopping preference impacted by age”?
The original customer table has a date of birth field. With the introduction of a data privacy vault, the plaintext date of birth is stored in the vault and a token representing the date of birth is stored within the application database. To determine if shopping preference is impacted by age, we can’t use just this token.
Instead, we need to perform a transformation on the data during ingestion to the data warehouse, splitting the date of birth into separate date, month, and year components, and only storing the component needed to compute approximate age (the birth year).
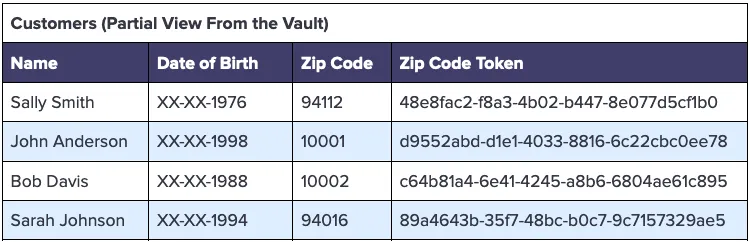
This transformation is supported natively by the vault when the Date of Birth column is configured to mask the date to match our use case. By exposing only the year and redacting the remainder of each customer’s date of birth, we redact the data that would potentially identify an individual – so MM-DD-YYYY becomes XX-XX-YYYY.
A partial view of the Customers table in the vault, with these redaction and tokenization settings, would look like the following:
The Transactions table within the warehouse would look similar to what’s shown below.
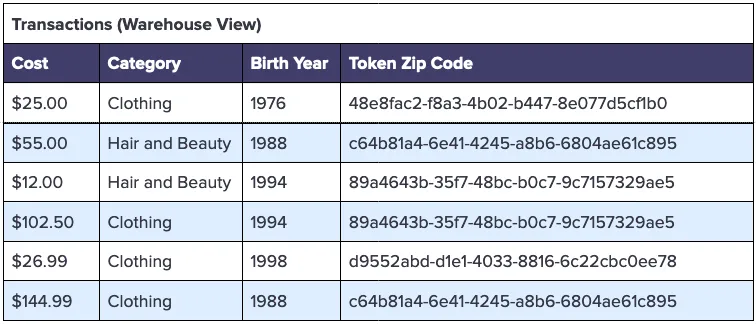
With the data in this format, you can write queries like the following to analyze customer cohorts by age, purchase category, and zip code:
You can mix and match these categories as needed without exposing your data warehouse or downstream analytics to any customer PII.
Question 4: “Are there different spending habits by credit card issuer”?
In this final use case, you need to segment customers by the types of credit cards they use. You can identify an issuing financial institution (Visa, Mastercard, etc.) from a credit card number by inspecting the first 6-digits of the credit card; these digits are the Bank Identification Number, or BIN. Of course, credit card information is highly sensitive and we don’t want to replicate this card data to our data warehouse or downstream services.
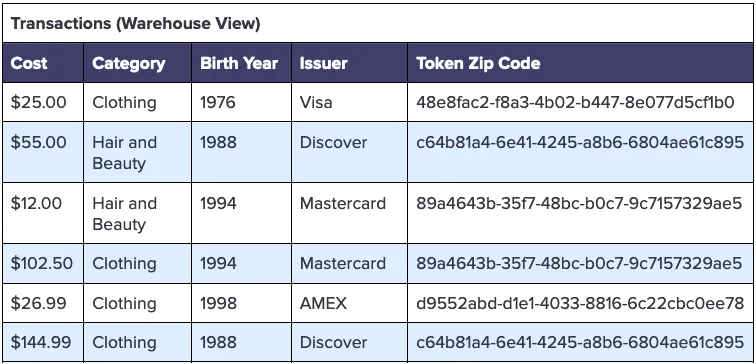
The first step to answering this question while protecting these credit card numbers is to store these numbers in the data privacy vault using a special deterministic BIN-preserving tokenization format. By applying this tokenization format to the credit card column for the vault Transactions schema, we get tokens that preserve the first six digits of the credit card, while substituting the remaining digits for random (tokenized) values, as follows:
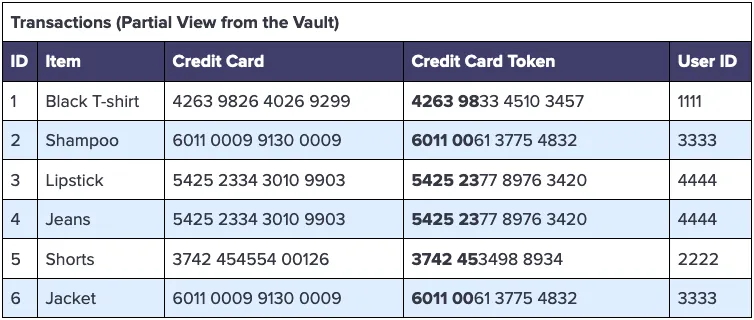
With the first six digits (the BIN) intact, the ingestion pipeline into the warehouse can convert these BIN codes into issuer names, and store that data instead of payment card tokens, as follows:
Preserving Privacy When Tokens Aren’t Enough
As we’ve explored, you can perform many common analytics workflows without handling sensitive data values by utilizing tokenized data and intelligent pre-processing. However, there are analytics questions that can only be fully answered by using some amount of PII.
For example, in a healthcare analytics scenario, we might want to answer a question like: When patients have an appendectomy and stay in the hospital for two or more days longer than average, are they readmitted more or less frequently than other patients?
This operation would require several computations over time-based and categorical sensitive fields, which would be difficult to do directly against only tokens.
We can solve this by integrating the vault with the data warehouse. For example, in Snowflake, you can create an external function that securely calls detokenize as part of your query operation. The detokenize function automatically utilizes the built-in privacy and security features of the vault.
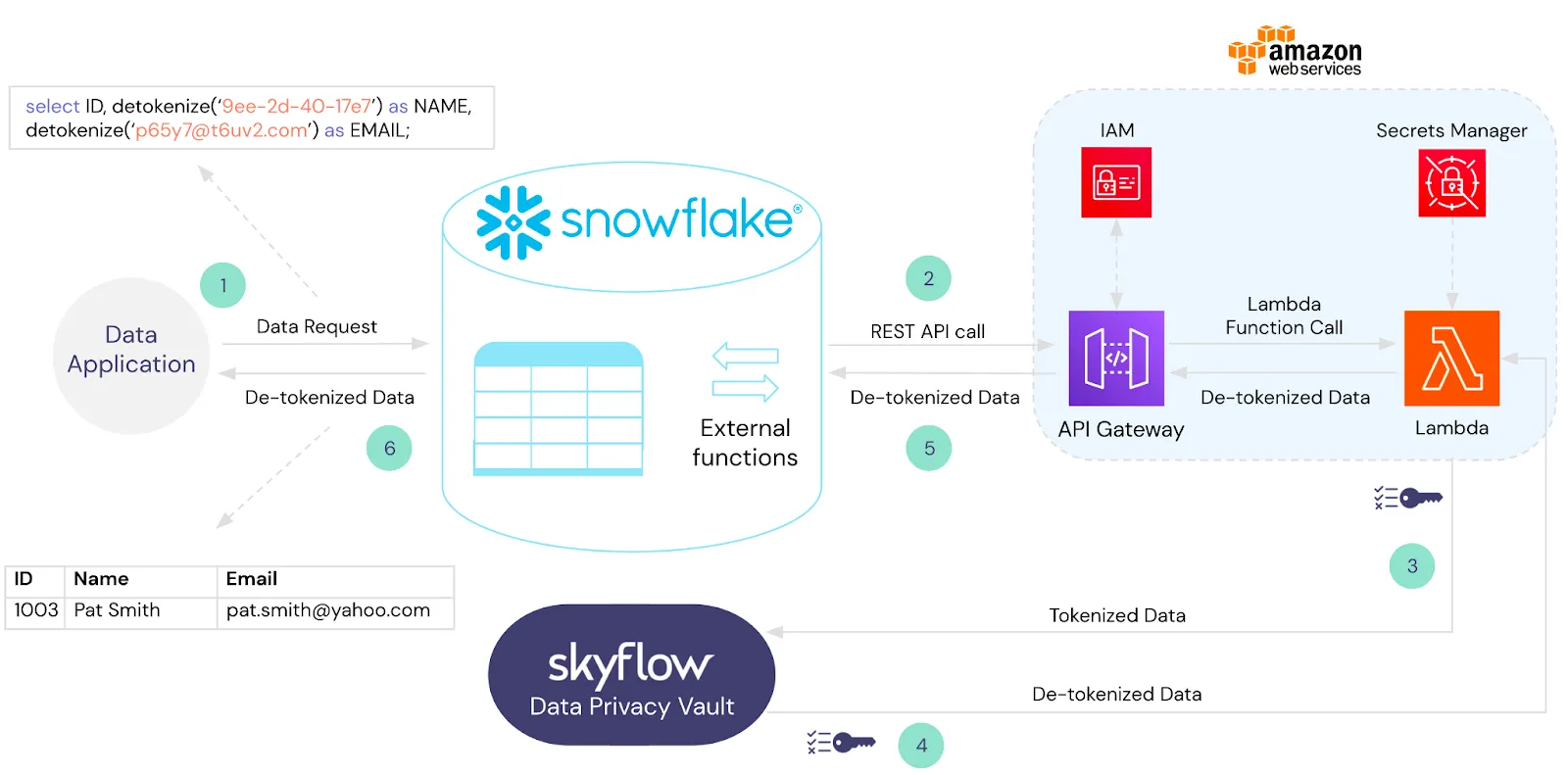
For example, the following query computes how many patients were readmitted after an appendectomy and a hospital stay that was two or more days above the average:
And, this second query computes the size of the cohort that stayed longer than two days above the average:
From these two queries, you can calculate the readmittance rate for this cohort. You can use a similar set of queries to calculate the readmittance rate for patients outside of this cohort.
Building for Privacy-Compliant Analytics
Creating a privacy-aware analytics pipeline is about improving your privacy posture and reducing your compliance scope. With the data privacy vault architecture, you’re shifting responsibility for compliance, data security, and data privacy from your pipeline, warehouse, analytics, and reporting tools to a vault that’s designed to protect the privacy of sensitive data.
As shown above, by using a combination of intelligent precomputed transformations and tokenization, you can continue to execute most analytics workflows as you do today, but without exposing your systems to PII. Finally, for very specialized operations that require analytics directly against PII, you can use polymorphic encryption and detokenization to provide secure and privacy-preserving analytics within your warehouse.
All of these features are available in Skyflow Data Privacy Vault. To learn more, please request a demo.