
How to De-identify and Secure PII in Snowflake
If you’re aggregating data from multiple sources into Snowflake AI Data Cloud, despite your best efforts, you’re likely to end up with sensitive PII in data workloads. In this post, I explain how to use Skyflow’s Native App for Snowflake to de-risk and de-scope data privacy, security, and compliance from your data pipelines, so you can leverage the power of Snowflake while protecting PII.
To understand de-identification better, let’s consider the data lifecycle for a fictitious company called Instabread as it looks to preserve the data privacy of their gig workers. This company provides a “bread marketplace” where clients shop for bread available at local stores from the comfort of their homes and on-demand shoppers handle tasks like pickup and delivery.
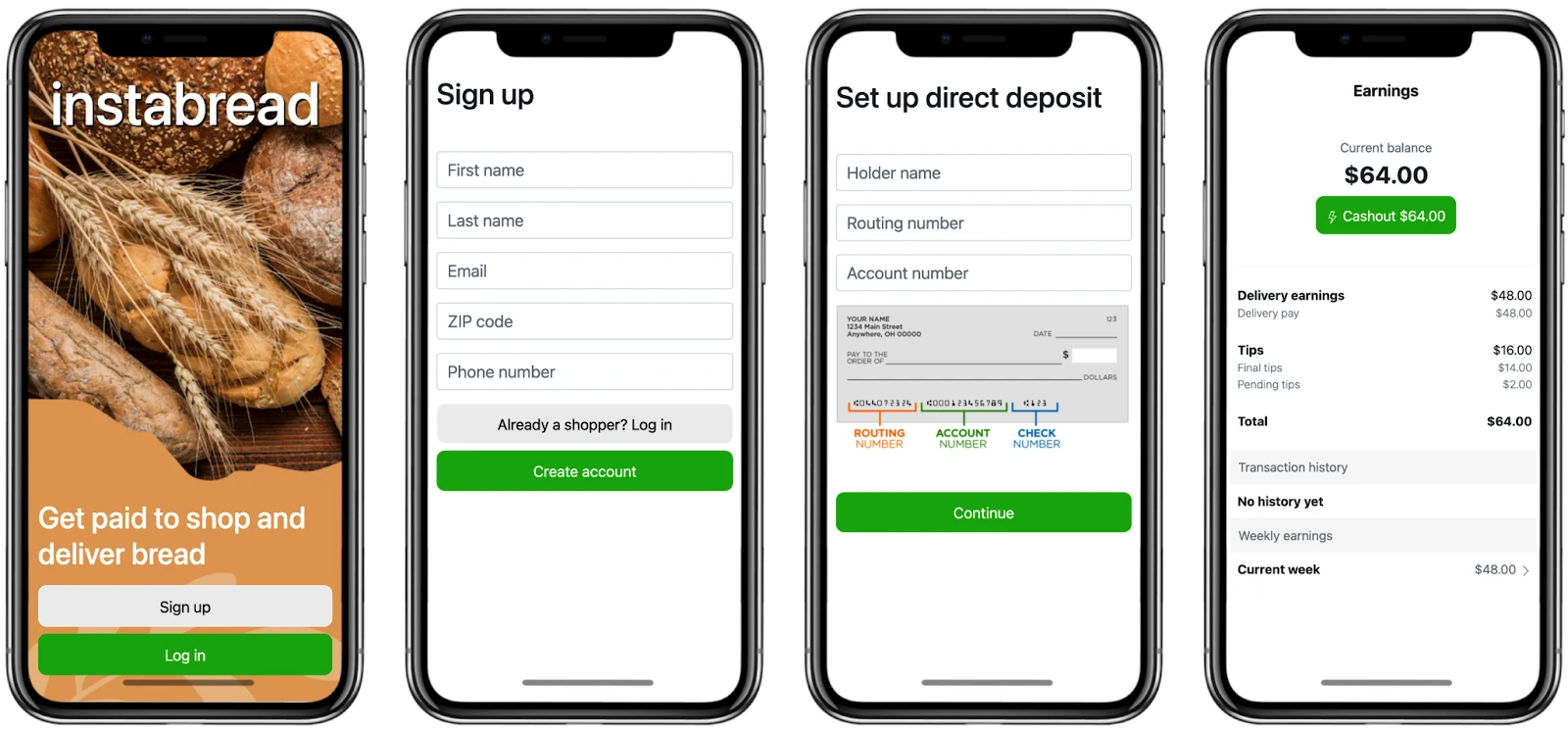
Instabread needs to create a mobile app where gig workers can sign up to become Instabread shoppers. As part of this process, Instabread needs to collect PII like the shopper’s name, email, home address, and banking information.
Instabread wants to be able to take advantage of modern cloud technologies like AWS and Snowflake, while avoiding the problems that come from intermixing user PII with regular application data (more on this available here).
To solve this problem, Instabread will use a Skyflow Data Privacy Vault to isolate and protect the PII of shoppers, transforming sensitive data into de-identified tokens. The token representation of the data carries no sensitive information but still preserves downstream workflows. Let’s explore how to architect this system while still giving Instabread the full power of AWS and Snowflake.
Instabread Requirements, Features, and Technologies
As part of the Instabread marketplace, Instabread shoppers need to be available for on-demand bread shopping and delivery. To address this need, Instabread is launching a new Instabread Shopper mobile app to recruit gig workers, coordinate shopping requests, and pay shoppers for deliveries.
Here are the high level requirements for the Instabread Shopper app:
- Mobile First: Shoppers are constantly on the go, so the app must support a mobile signup experience
- PII Collection: To create shopper accounts, the app must securely collect and store shopper user data like name and email address
- Bakery Selection: Shoppers must be able to select which bakeries and stores they are willing to travel to based on where they live
- Banking Information: The signup experience must securely collect and store bank account and routing information
- Paying Gig Workers: Shoppers must be able to receive prompt payment for completed deliveries
- Analytics: Sign up data must be stored securely in the Instabread data warehouse and be available for analysis to inform business decisions
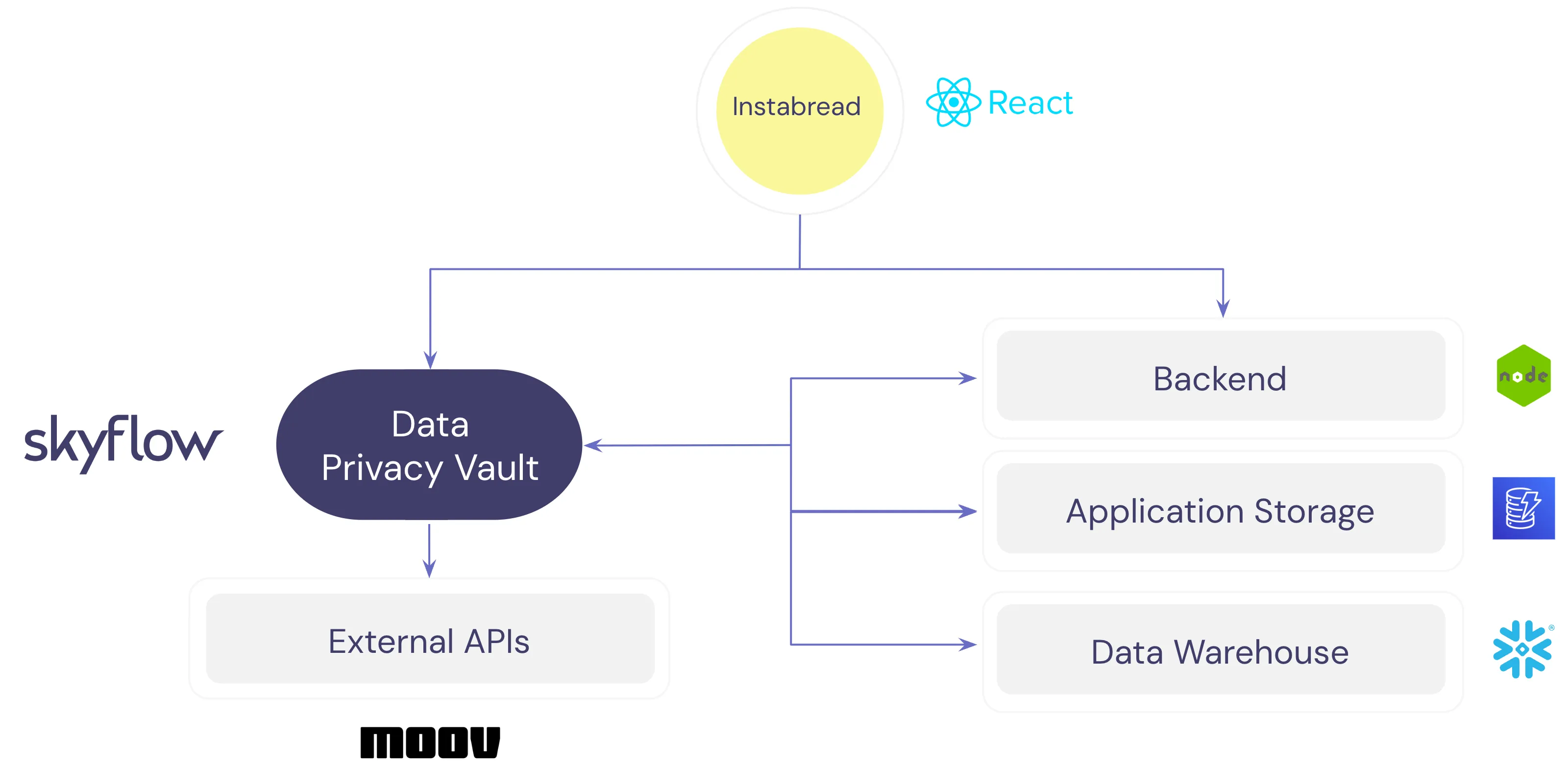
A combination of technologies are needed to support these requirements. The image below shows a high level overview of the technology stack. AWS DynamoDB is used for application storage, Snowflake is used for warehousing and analytics, and Skyflow’s Data Privacy Vault provides secure storage and controlled access to PII.
To support money movement from the Instrabread bank account to a gig worker’s bank account, the application uses moov.io securely to relay data from the vault using Skyflow Connections, as shown below:
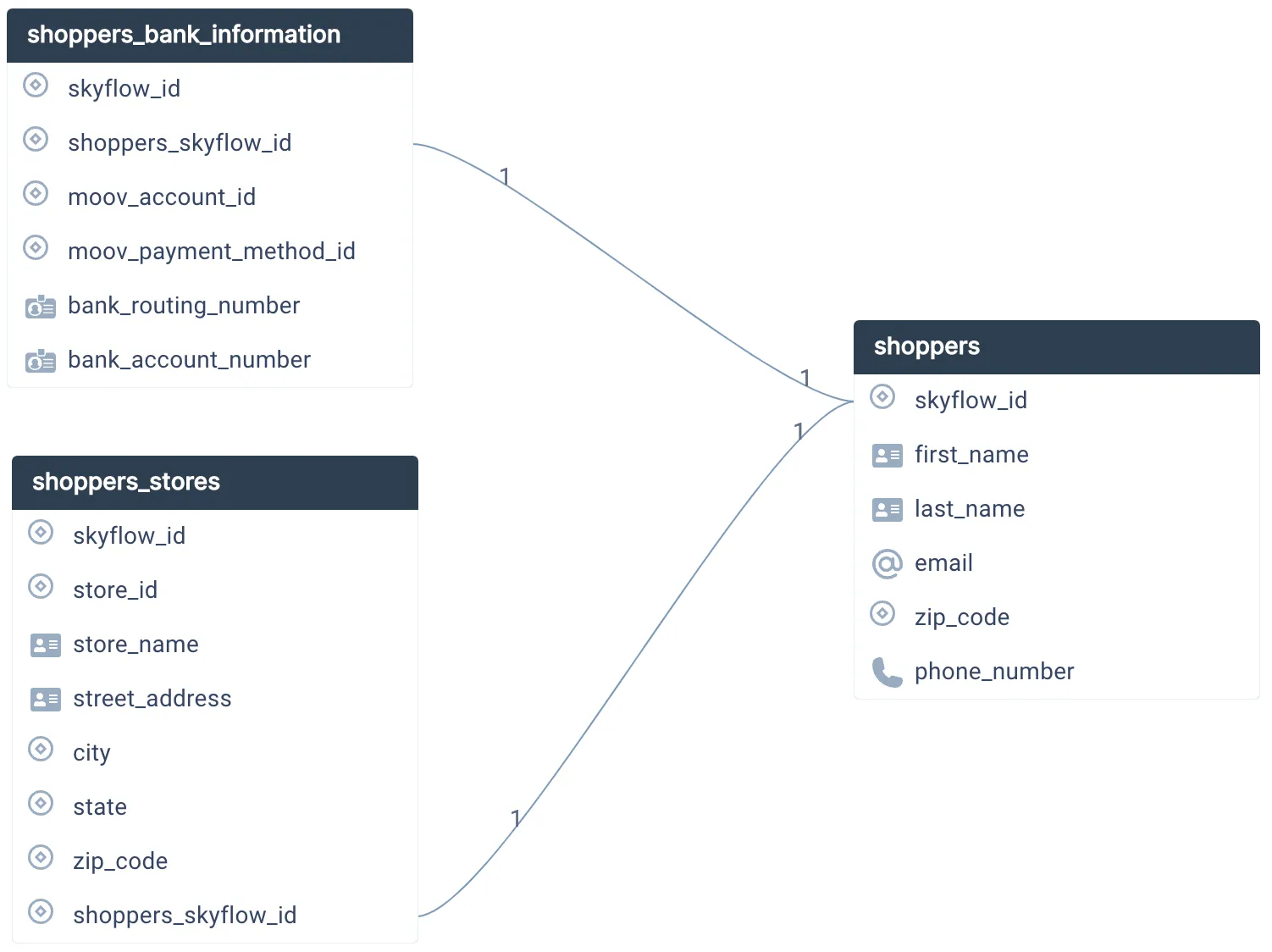
The original plaintext values for Instabread gig workers’ PII are stored in the vault based on the schema shown below. A similar structure exists in DynamoDB, where tokenized data and other application data is stored.
Collecting and De-identifying Sensitive Data
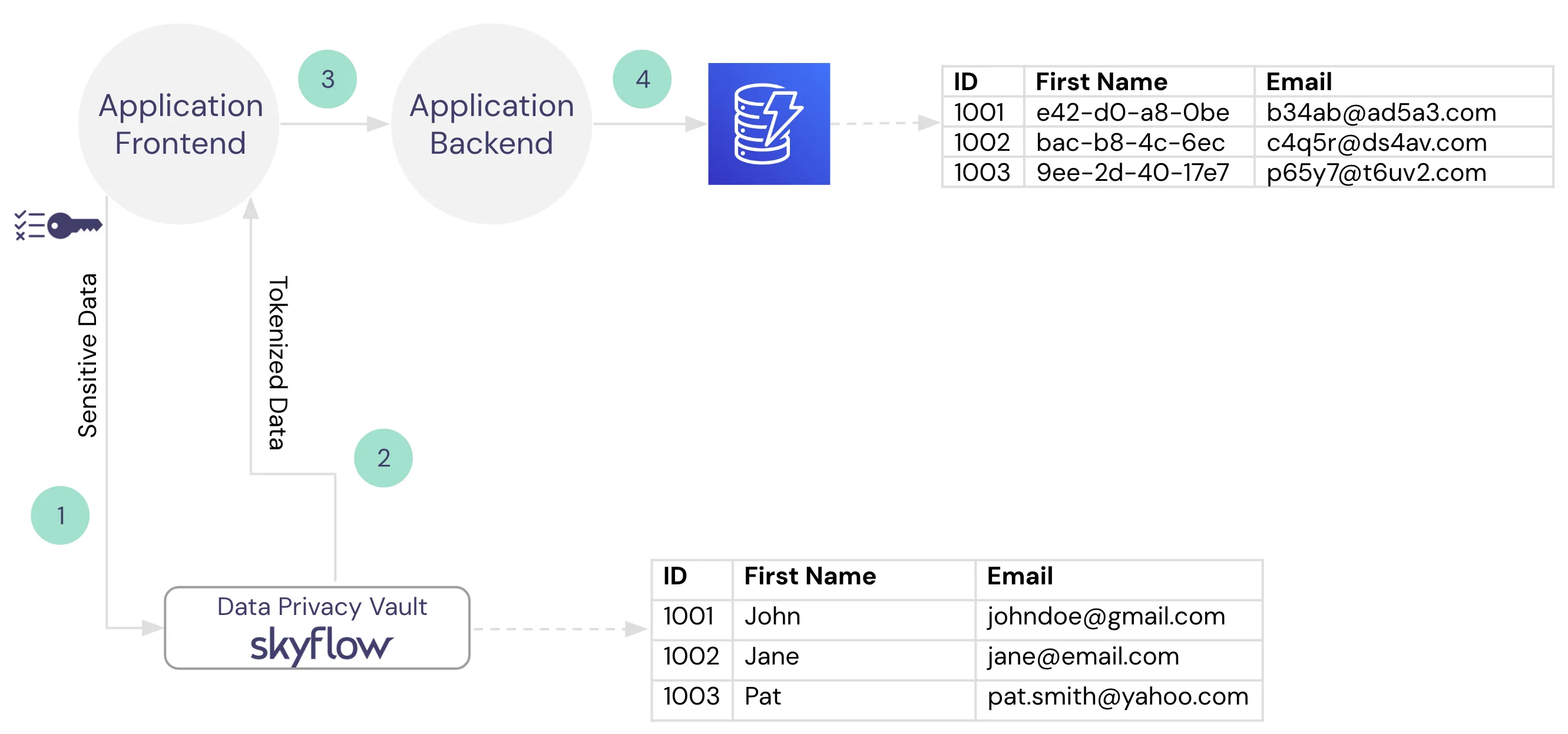
When collecting PII, the ideal scenario for data privacy and security is to de-identify sensitive data as early in the data lifecycle as possible. In the case of Instabread, in any part of the sign up process where PII is collected, that data should go directly to the Data Privacy Vault without touching any of the backend systems. The Data Privacy Vault will return tokenized data that can be used as a stand-in for the original values (like a pointer) for running various workloads but has no exploitable value.
This means that during account creation, when Instrabread collects the name, email, zip code, and phone number the plaintext values should go directly to Skyflow. Similarly, when a routing and bank account number are provided by a shopper, that data should not touch any of the Instabread application infrastructure – instead, it is stored and transformed by the vault. In exchange, Skyflow returns tokens that can then be safely sent and stored in the downstream services.
We can accomplish this easily by using a Skyflow client-side SDK. The sample code below shows the vault insert request. Tokenized data will be returned from the insert function call.
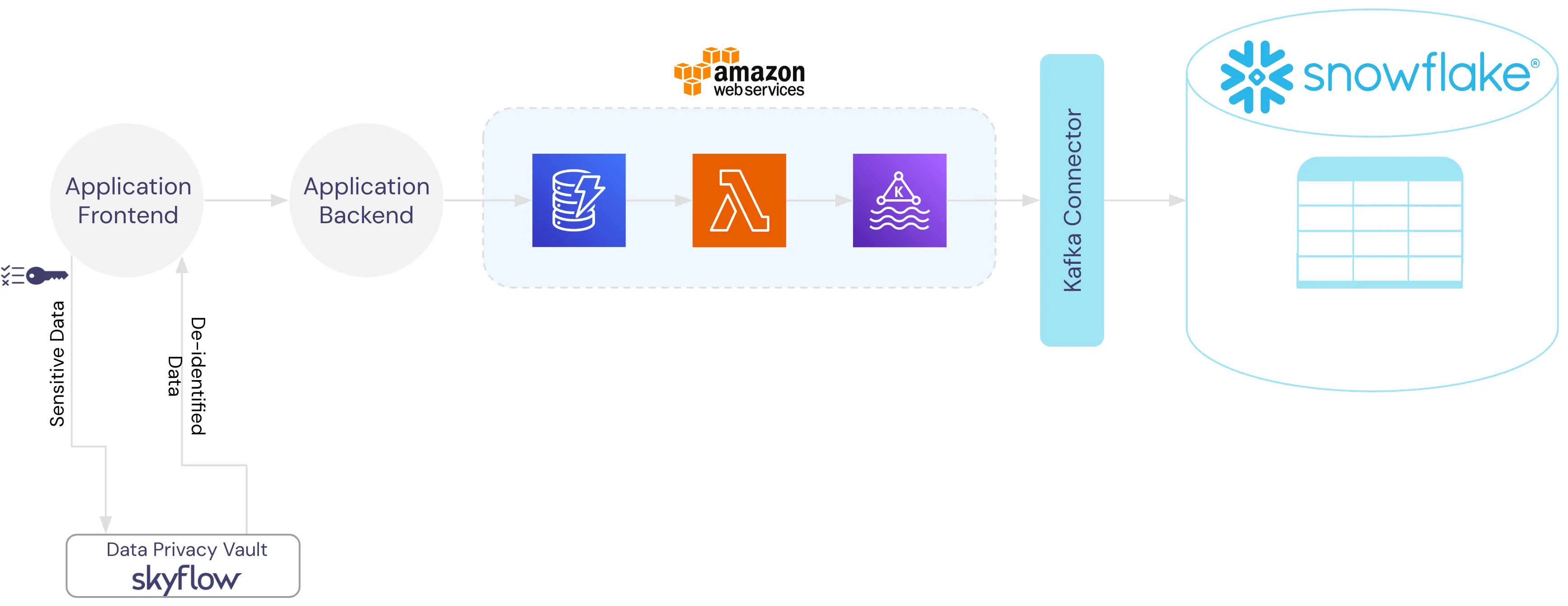
The image below shows the data flow diagram for PII collection in Instabread. Sensitive data is sent directly from the application frontend to the Data Privacy Vault, tokens are returned and those tokens are passed downstream to the application storage in DynamoDB.
Moving Data Downstream to Snowflake
The data that ends up in DynamoDB also needs to be sent through an ETL pipeline to the Instabread Snowflake data warehouse to support analytics.
To manage this, we’ll set up an AWS Lambda to automatically trigger whenever new data is added to DynamoDB. The Lambda function writes the newly-added data as a message to a Kafka broker. Then the Kafka Connector feature of Snowflake ingests the messages and metadata from Kafka into a Snowflake table similar to the following diagram. Note that this is just one example of how this could work, you could use any combination of ETL tooling to facilitate real-time or batch loading of the data into Snowflake.
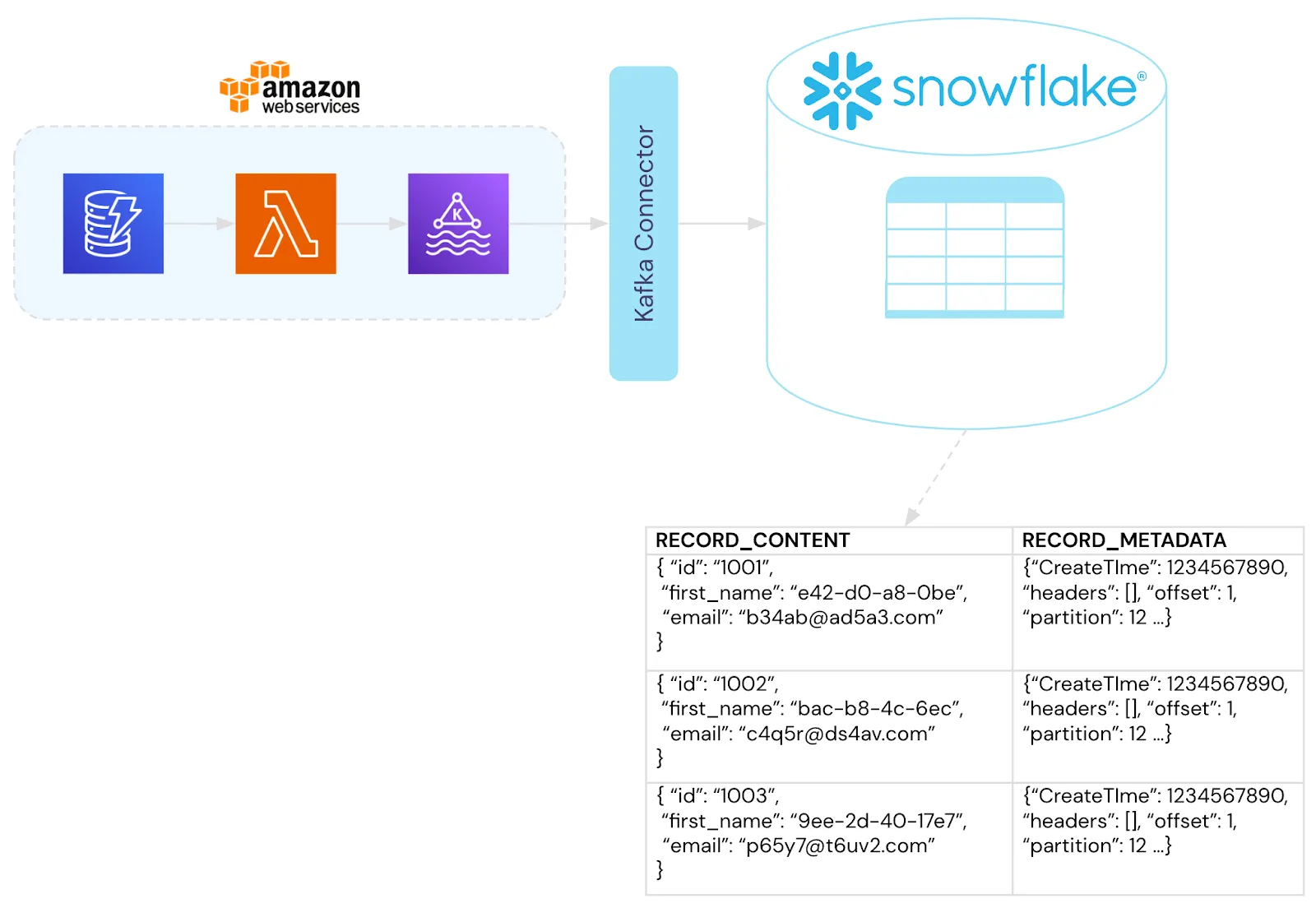
When putting it all together, the entire application infrastructure is completely de-risked and de-scoped from managing data security, privacy, and compliance. Those responsibilities are handled by the data privacy vault.
Querying Across Snowflake and the Vault
The data stored in the warehouse is now completely de-identified. We can execute many analytics workloads directly against the de-identified data.
For example, let’s say we wanted to know the breakdown of shoppers by zip code so we can compute the gig worker density in each geographic area.
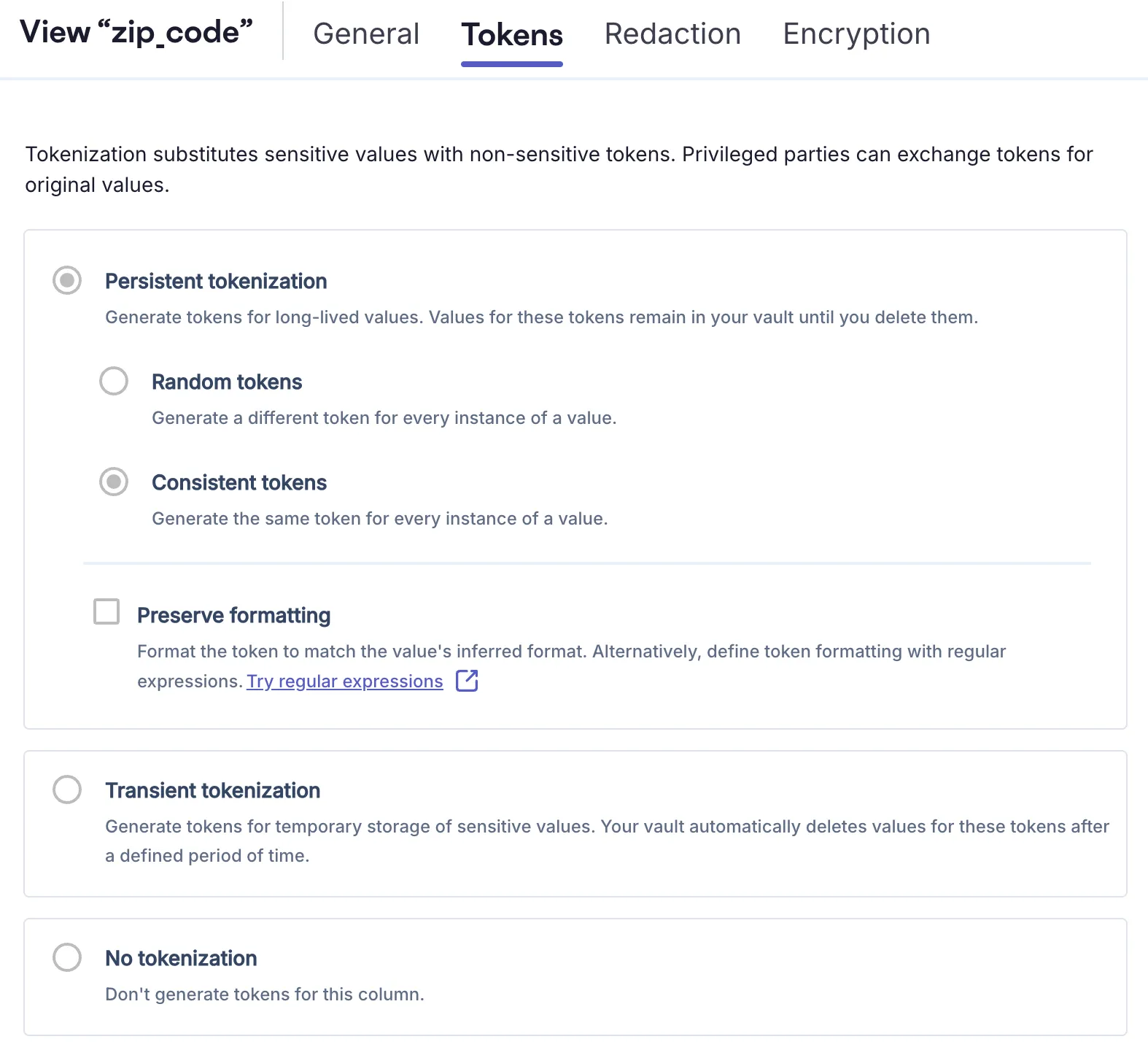
As shown in the image above, the tokenization format for zip code in the Instrabread vault is a consistent token. This means the same zip code will always be tokenized to the same UUID.
This tokenization format lets us write a group by query much the same as you would if you were storing the actual shopper zip codes within Snowflake:
However, there could be situations where we want to get the original plaintext value to provide additional context for analytics results. In the zip code example, the query we discussed before could be used to generate a bar chart view of the results. But, to be useful to the person viewing the bar chart, the x-axis labels should correspond to an actual zip code, not UUIDs.
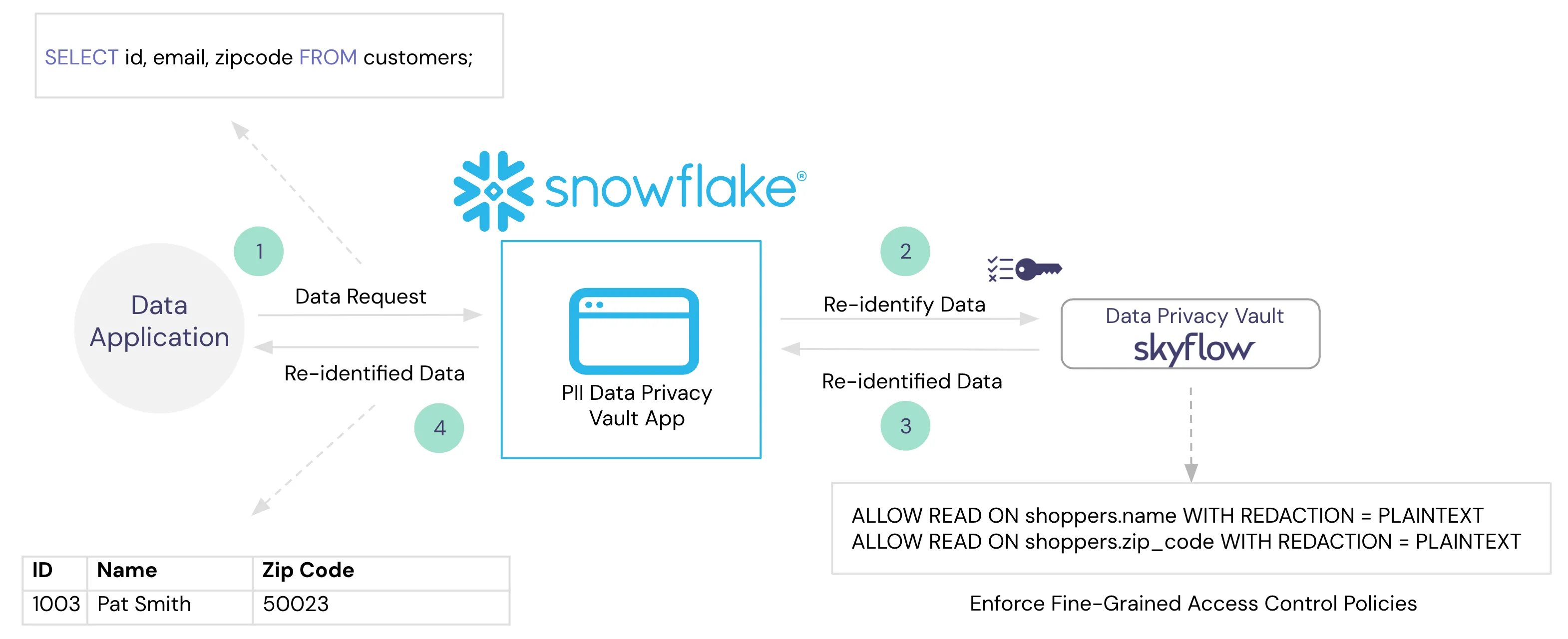
To support this use case, Instabread needs a way to detokenize the tokens stored within Snowflake while enforcing the fine-grained access policies to make sure only authorized people are able to see the customer data. Enter Skyflow's Native App for Snowflake.
What is Skyflow's Native App for Snowflake
Snowflake Native Apps are self-contained applications that live within the Snowflake data platform. Instead of having to bring the data to your app, you bring your app to the data. Developers can take advantage of Snowflake’s security, scalability, and performance without managing their own infrastructure. With Skyflow's Native App installed within your Snowflake account, you can transform data during query operations based on the policies you create and control with your vault.
This makes the integration and use of Skyflow seamless for analysts and helps give you another tool on top of Snowflake's existing security model to reduce the risk of PII exposure.
Using Skyflow’s Native App to Detokenize Data from Snowflake
To get started using the Native App for Instabread data analytics, we need to install the app into our Snowflake account and then we can connect the Instabread vault directly to Snowflake.
With the app installed and the vault connected to Snowflake, all fine-grained access policies configured in Skyflow will be automatically applied to sensitive data.
You can now execute a query like the one below directly from a Snowflake worksheet. The query will return the re-identified value that corresponds to the token provided you have permissions to view that value.
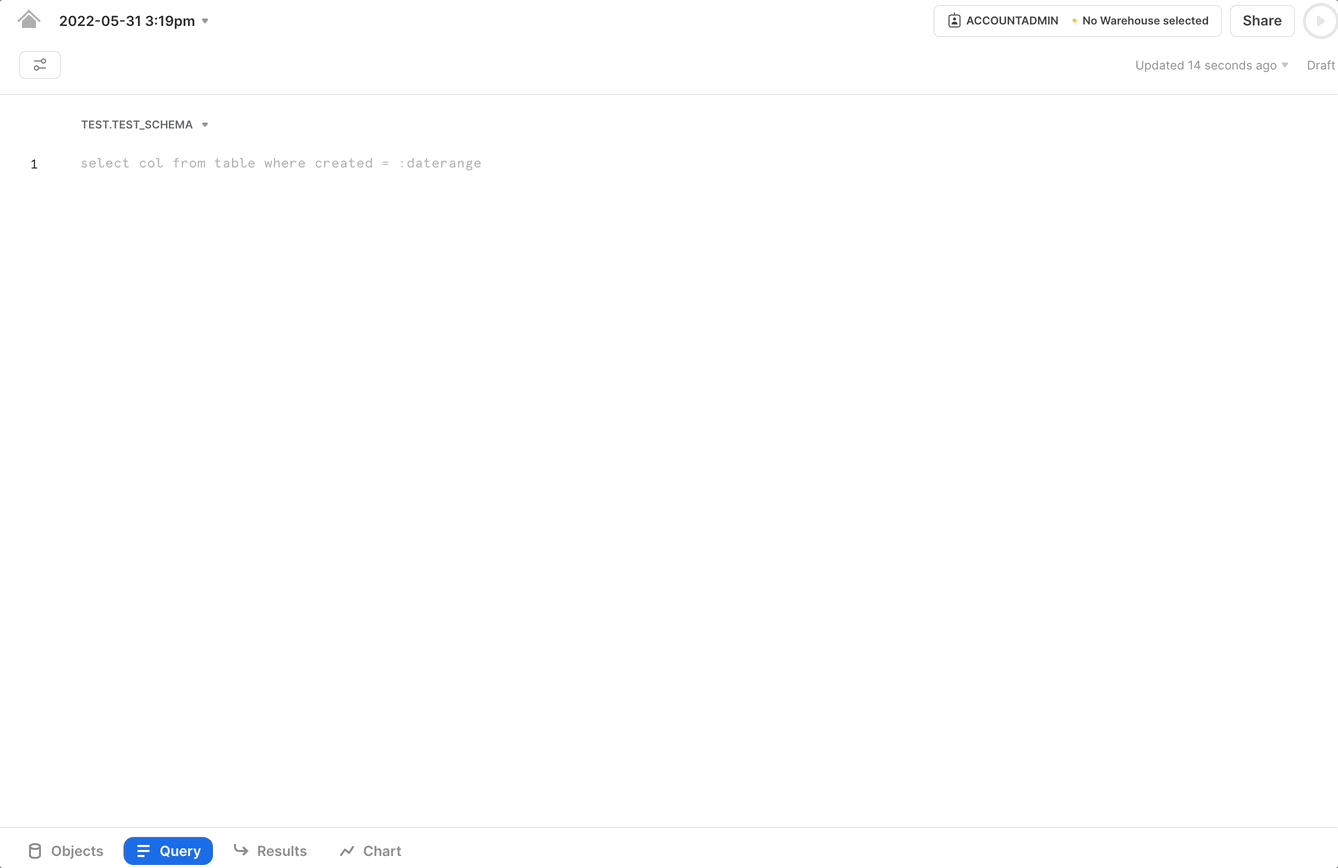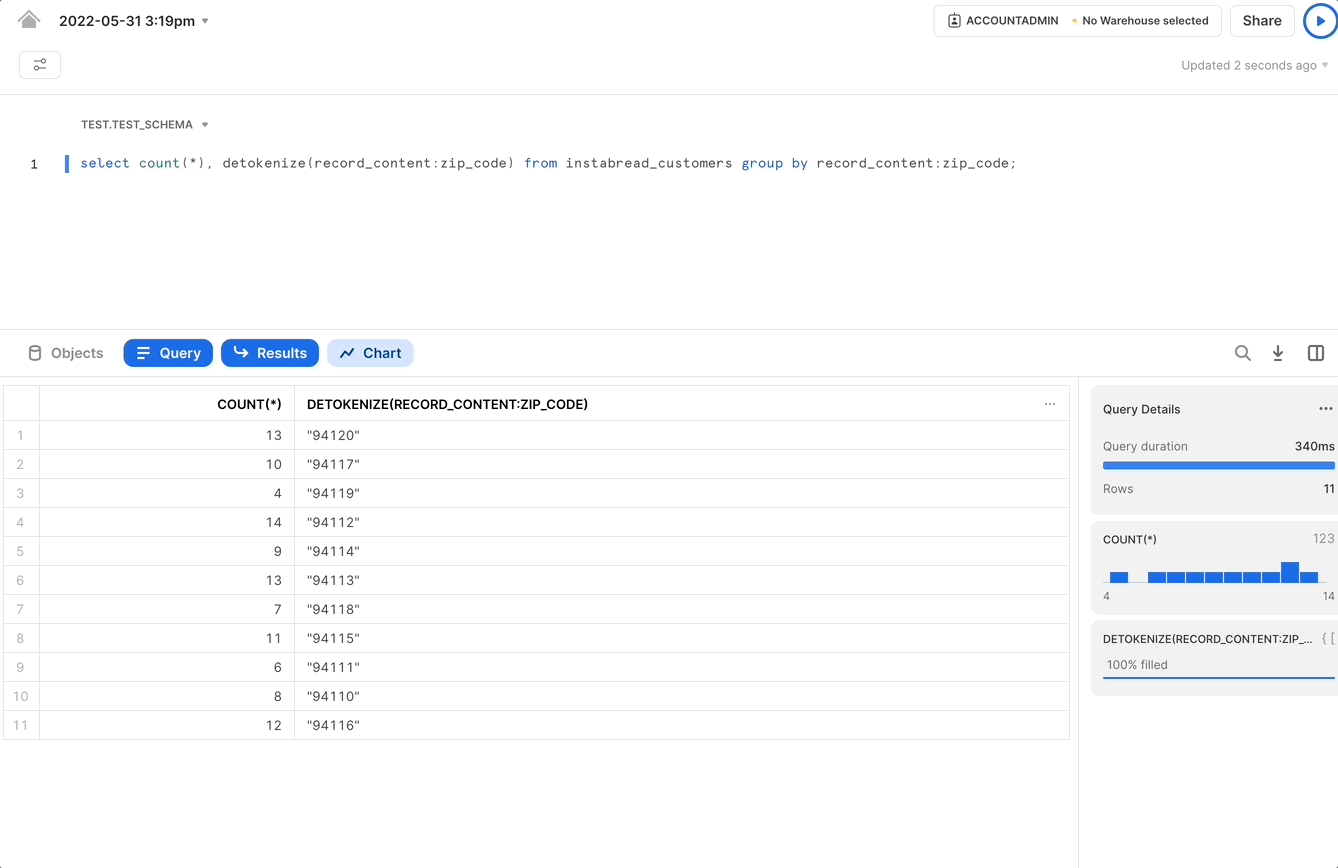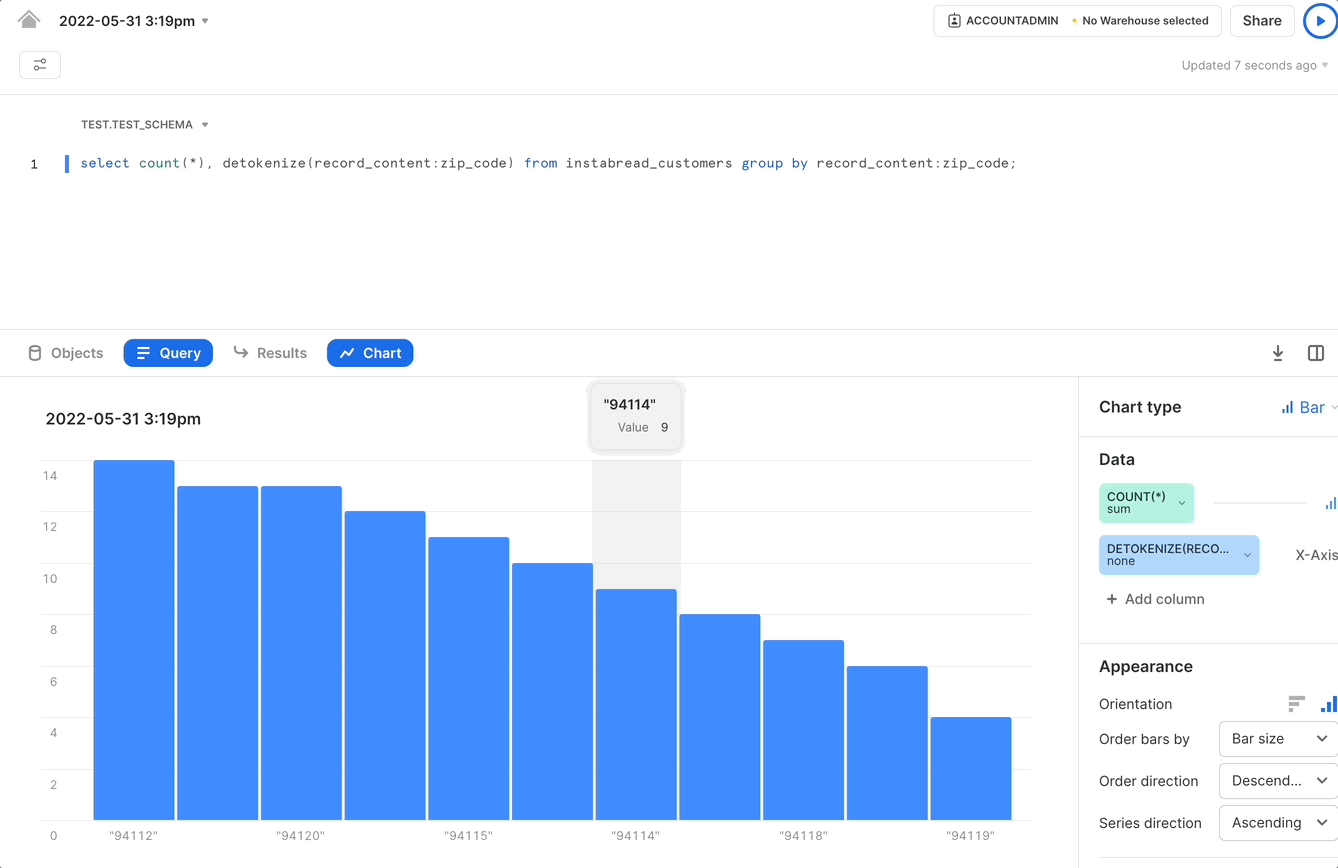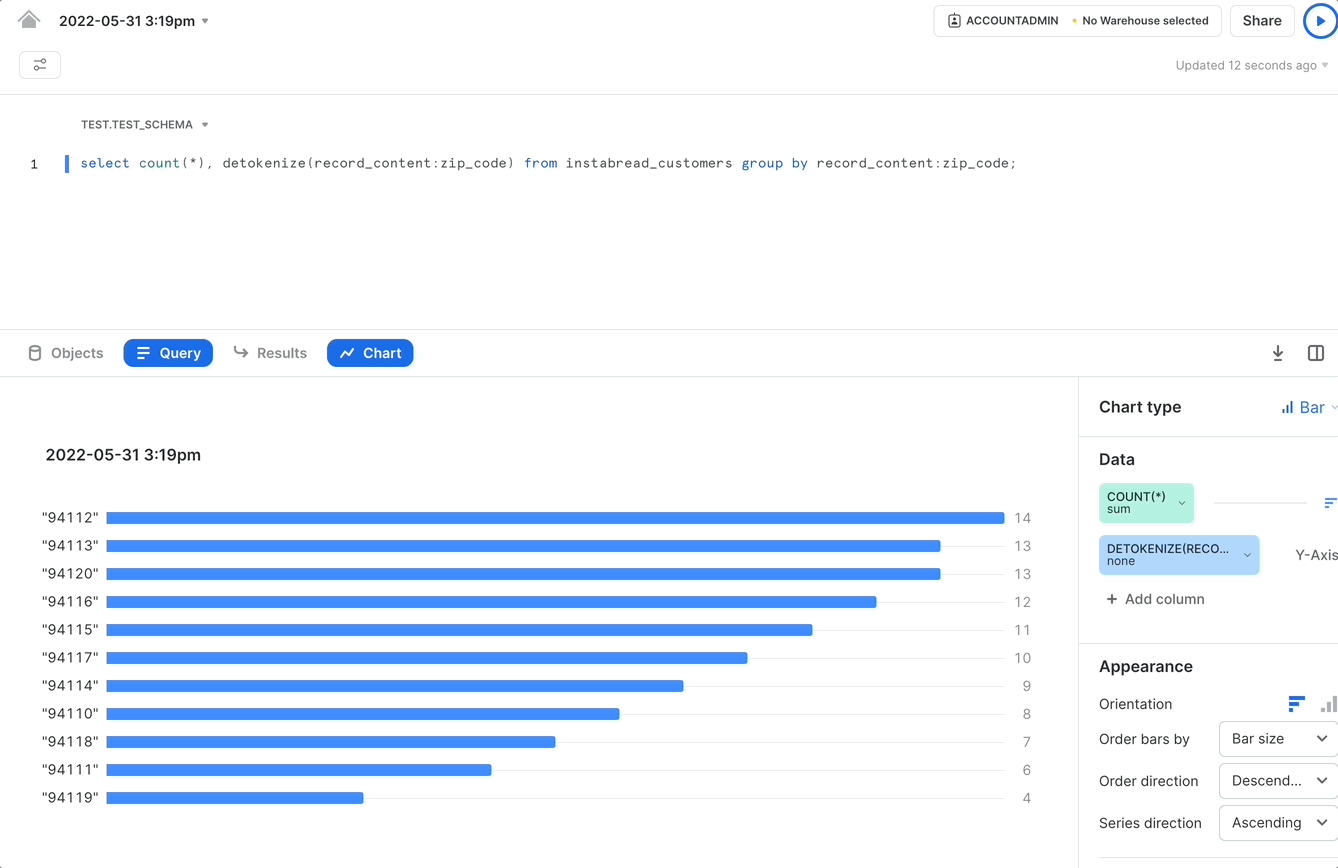
To perform the analytics operation discussed earlier, computing gig worker density by zip code, we can accomplish that task using a query as follows.
The results for this query can power a graphical representation of gig worker density as shown in the following GIF:
Easy Data Protection and Compliance for Analytics
The Instabread use case illustrates how you can easily have data protection and compliance while also supporting typical analytics workloads provided by Snowflake Data Cloud. Further, by leveraging Skyflow’s Native App for Snowflake, data can be re-identified when necessary directly from Snowflake based on the policies you put in place. This simplifies data access control holistically across your stack and reduces the risk of PII ending up in a data breach
This example showed the full lifecycle of data, from collection to usage, but only for a single source. In a real application, additional sources of data, both structured and unstructured, might be inputs to your warehouse. Detection and de-identification of sensitive data for these additional sources is easily supported through further integrations with the Skyflow APIs.
To explore using a Skyflow Data Privacy Vault to de-identity and secure PII, give Skyflow a try.