
De-identifying Analytics Data: An AWS Sample Application
If your company has a data analytics pipeline to a data warehouse, you’re right to be concerned about the impact of aggregating customer PII, PHI, and PCI on data privacy and security. In this post we’ll explain how you can de-identify data in a pipeline built on AWS so you can use sensitive data while preserving privacy.
Previously, we discussed that sensitive data often ends up in data analytics pipelines and covered some of the challenges you’ll face trying to ensure privacy for this data (see De-identifying Analytics Data With Skyflow).
In this post, we’ll look at a privacy-preserving data pipeline sample application that we’ve developed. This sample application uses the Lambda and DynamoDB features of AWS (along with Kafka and Redshift) and is available on GitHub.
Of course, a one-size-fits-all approach to preserving privacy when ingesting data doesn’t work because data ingestion pipelines are as varied as the companies they serve — and the analytics use-cases they support. However, the general approach shown here is applicable to other data ingestion pipeline architectures.
Check out our video on de-identifying analytics and why we created this sample application at the end of this post.
Data Analytics Pipelines without De-identification
Many large companies, including healthcare companies and retailers, have data analytics pipelines. For example, let’s say that you work for a nationwide hospital operator. You need to aggregate data from multiple hospital databases into a single healthcare data warehouse so you can run company-wide analytics to reduce costs and improve patient care outcomes. Such analytics often require data that’s part of a larger dataset. And that dataset might include sensitive data that you don’t need for analytics and that you’d rather remove or de-identify.
When sensitive data ends up in your analytics pipeline and ultimately in your data warehouse, it becomes available to anyone running analytics throughout your organization. Not only does this create a bigger target for data breaches, but it can also cause compliance headaches. And of course, the privacy of this data isn’t improved by replicating it into a data warehouse.
Without De-identification: A Pipeline with Problems
To see what happens when you build an analytics pipeline without de-identifying data, consider a scenario where you aggregate sales data from each of a retailer’s regions into a single data warehouse:
- Company-wide data visibility reduces data privacy: PII once visible to the manager of a single region is now available to anyone who has access to the data analytics warehouse.
- Increased data breach vulnerability: Analytics is enabled, but a company-wide data breach becomes much more likely because the warehouse provides a single source for all customer PII managed by your company.
- Unnecessary collection of additional sensitive data: Your analytics pipeline can collect sensitive information that you don’t need for analytics, meaning you incur the risk of this data being breached when it never should have been aggregated in the first place.
Here’s an architecture diagram for an example analytics pipeline with these types of issues:
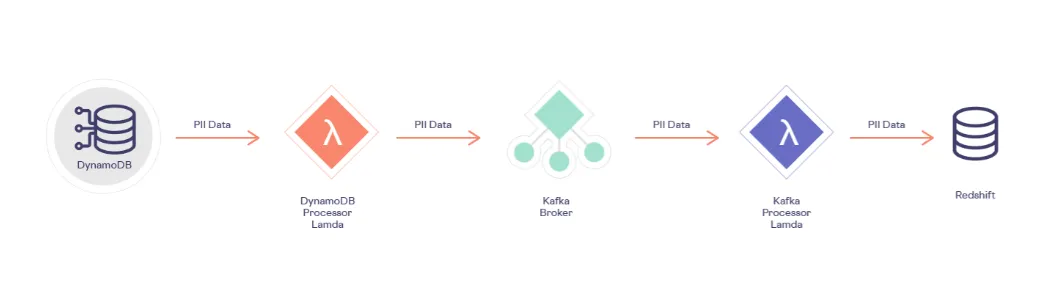
Why not permanently de-identify all of the sensitive data in your analytics pipeline? Sure, that addresses the problems described above, but this approach has its own problems:
- Analytics often requires some sensitive data. A blanket approach where you de-identify all data and can’t re-identify it won’t work because your analytics might need certain types of sensitive data to function properly, like customer age or zip code.
- Analytics might not provide usable results without re-identification. Yet another drawback of permanently de-identifying all sensitive data in your pipeline is that sometimes you might need sensitive data in the output of your analytics operation, like the email addresses of customers of a particular age range in a given zip code.
So, what’s the solution? To de-identify data in an analytics pipeline and still get value from analytics, you need a system that lets you replace any sensitive data going into your analytics systems with tokens. This lets you keep sensitive data secure without causing issues with analytics or sacrificing data usability.
Add De-identification to Your AWS Pipeline with Skyflow
Adding de-identification to the above AWS analytics pipeline with Skyflow is easy; here’s what you need to do:
- Create an ETL pipeline: Create a streaming or other data ingestion pipeline, and use a stream subscription or other method to notify your pipeline when sensitive data is added or updated in your upstream database.
- Store sensitive data in Skyflow, send de-identified data to the pipeline: The stream or similar notification triggers a “task” that calls Skyflow APIs and stores sensitive data in your Skyflow data privacy vault, and then sends de-identified data to the data analytics ingestion pipeline.
- Store de-identified data in the warehouse: The analytics processor then stores the de-identified (tokenized) data in the data warehouse.
Here’s an architecture diagram for an analytics pipeline and data warehouse that uses Skyflow for de-identification:
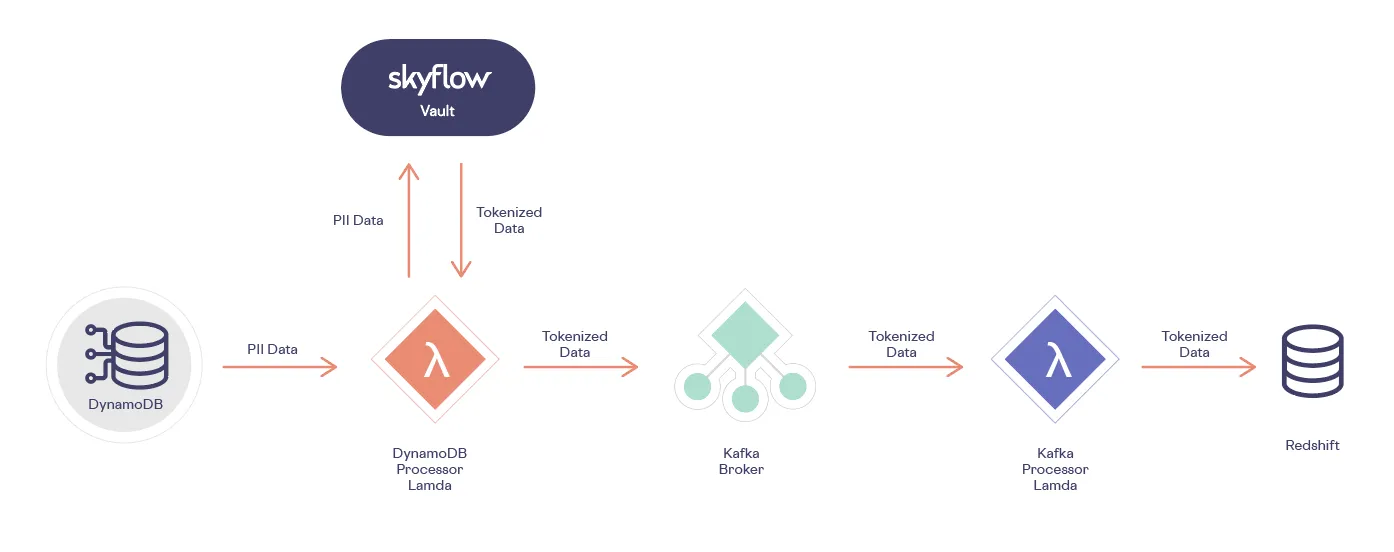
Next, let’s look at how this updated architecture enables analytics while preserving data privacy.
De-identified Analytics Without Anxiety
Now that you’ve de-identified data in your analytics pipeline, you can enjoy the benefits of powerful analytics without worrying that you’re creating the perfect target for the next high-profile data breach. Let’s take a look at some of the things that changed in our sample analytics pipeline:
- Sensitive data is stored in Skyflow: Sensitive data coming from the operational database is persisted in your Skyflow vault and the de-identified (tokenized) data is sent downstream to the rest of the pipeline.
- The data warehouse is free of sensitive data: The data warehouse now contains no sensitive data; instead, only the corresponding tokenized data is stored.
- Analytics remain actionable: When analytics output takes the form of tokenized data, you can re-identify it to make analytics insights actionable.
You can learn more about this sample application by cloning our AWS Analytics Demo GitHub repository: https://github.com/skyflowapi/aws-analytics-demo. Please note that while this sample application uses Kafka, the general approach used in this sample application is applicable to other data ingestion pipeline architectures. For example, you could use Kinesis or DynamoDB Streams to ingest data; or store data in other datastores, such as EMR.
Check out our video on de-identifying analytics and why we created this sample application:
To learn more about how Skyflow can help you get the most out of your data without compromising security, please get in touch with us.