
How to Keep Sensitive Data Out of Your Logs: 9 Best Practices
Millions of people have been impacted by the exposure of their sensitive data because it can often be found in companies’ log files and database backups. Read on to learn the best practices for keeping sensitive data out of your logs.
In 2018, Twitter accidentally logged 330 million unmasked passwords to an internal log. Fortunately, there was no indication of a breach, but this is just one example of many where a company’s logs contained sensitive data. Whether intentional or by accident, it’s important to take steps to prevent your logging system from being the weak link in your security and privacy infrastructure.
Robust logging is a core part of software development. Logs help developers and SREs to identify issues with features launched in live systems, track usage, and provide audit trails.
However, the security around logs can sometimes be lax in comparison to the security measures used to govern access to a production database. Additionally, there’s a temptation to log sensitive customer data, like names and emails, as an easy way to identify who’s responsible for the creation of an application event and create a strong audit trail.
Regardless of whether your business is in a particularly sensitive industry like fintech or healthtech, logging user PII is both a security and compliance risk. It’s been the culprit behind several high profile data breaches.
In this article we breakdown what sensitive data is, the dangers of logging it, and share the best practices for avoiding this problem.
Let’s get into it.
What is Sensitive Data?
Before jumping into the best practices, let’s first discuss what constitutes sensitive data. Sensitive data is private information that must be protected from unauthorized access.
This following is a non-exhaustive list of data that’s considered sensitive:
- Personally Identifiable Information (PII): This includes data like full names, addresses, email address, driver’s license number, and phone number
- Financial data: Credit card information and other financial data
- Healthcare data: Medical history and records
- Passwords
- IP address
Although the data listed above is considered sensitive and is regulated under compliance laws like GDPR, PCI, and HIPPA, it’s important to look at data sensitivity in the context of your company and product. For example, a zip code isn't considered sensitive PII, but you wouldn’t want this detail about your customers to end up in the public domain (and neither would they).
When logging any data, you should ask yourself, “What’s the likely impact to my business if this information ends up in the wrong hands?” If having this data leaked would damage your business and customer trust, then you should treat it as sensitive data and avoid logging it.
From a consumer's perspective, their data is their data, and news about a breach will hurt your business reputation, regardless of what data was compromised. In fact, according to McKinsey, 87% of consumers said they would not do business with a company if they had concerns about its security practices.
Understand the true risk of PII exposure – get the whitepaper →
The Dangers of Logging Sensitive Data
There are two big reasons for keeping sensitive data out of your logs — compliance and security.
Starting with compliance, under privacy laws like the EU’s GDPR and California’s CCPA, users have the following rights
- Request information about what data is persisted about them
- Get information about why their data is being stored
- Request deletion of personal data
Complying with any of these requests becomes extremely difficult if you have user data duplicated across systems and spread throughout your logs and database dumps and backups.
Historically, logs are often the target of data breaches or the source of accidental data leaks. Keeping sensitive data out of your logs is a simple way to address this issue. Attacks are going to happen, but by keeping sensitive data out of your logs, you’re significantly reducing the value of any data that gets compromised.
6 Best Practices for Keeping Sensitive Data Out of Your Logs
Now that we understand what sensitive data is and the dangers of logging it, let’s take a look at the best practices for avoiding these problems.
1. Isolate Sensitive Data
When you pass sensitive data like a user’s name, email, and address through your system, it’s much more likely to end up being logged by APIs or other systems and stored within your application database. Instead, you want to minimize the exposure your systems have to sensitive data by isolating it within a single source of truth like a data privacy vault.
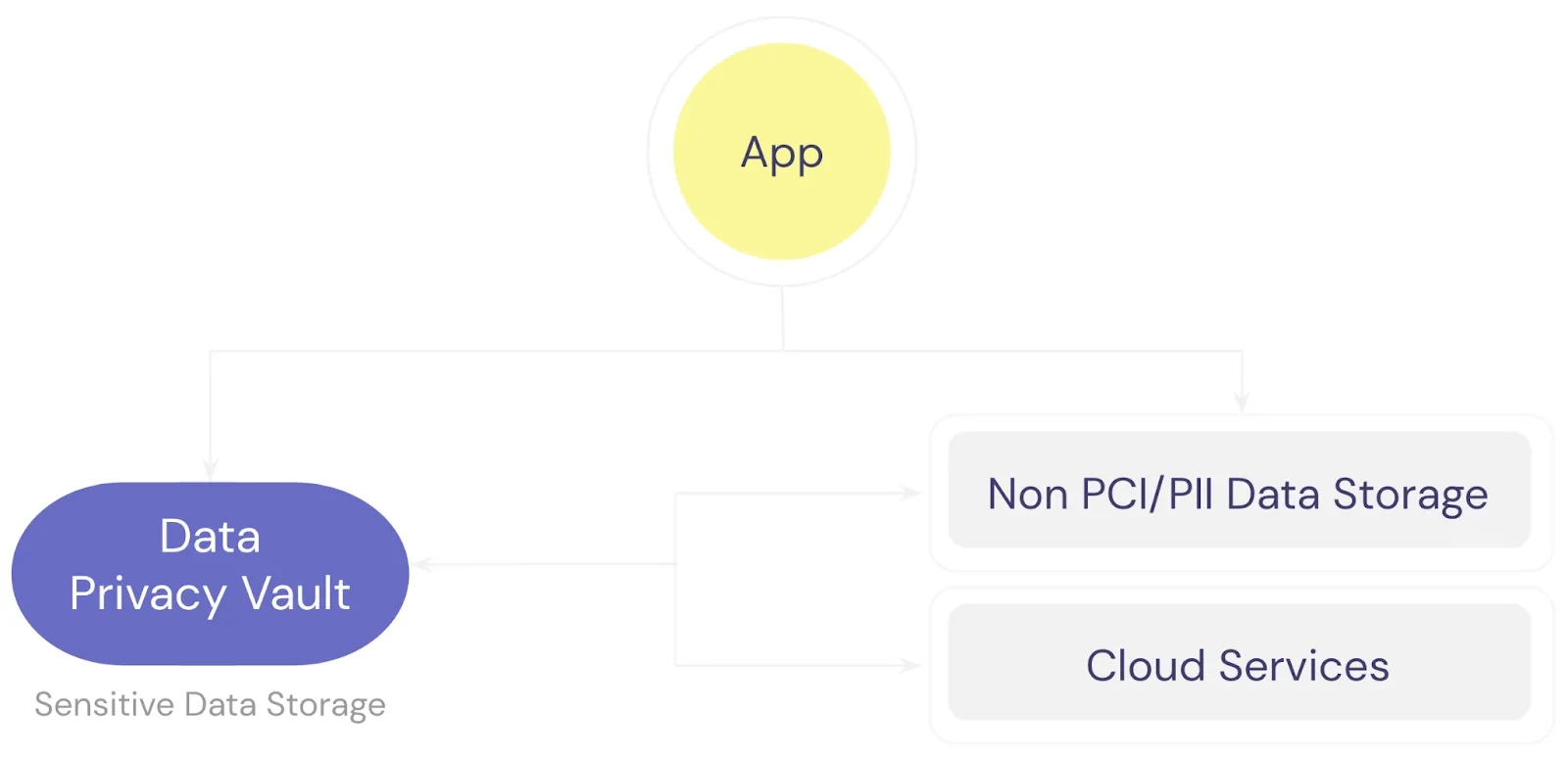
As shown in the image above, with a data privacy vault, all sensitive data is isolated and protected within the vault. Your application never passes sensitive fields through internal APIs or stores sensitive fields within the application database. This way database backups, SQL logs, application logs, and server logs can’t have any sensitive data because it’s never present in the systems being logged or backed up.
2. Log Tokens, Not Values
When writing application logs, there’s a temptation to include an identifier for a user, like their name or email. This can help with debugging, but despite the convenience, you need to avoid it.
A simple way of avoiding this is to log a reference to the raw value through a process like tokenization. With tokenization, you swap the sensitive data for a token.
For example, if you tokenize a customer’s email, like “joe@acme.com”, it gets replaced by an obfuscated (or tokenized) string like “bwe09f@fg7d8.com”. In this example, we’re using format-preserving tokenization, so the token is structured like a valid email address but has no exploitable value and can be safely written to a log.
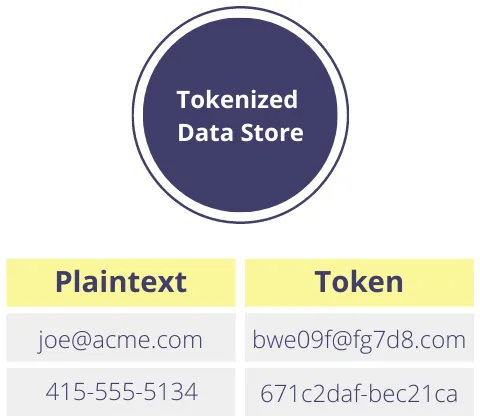
With your sensitive data isolated and secured in a data privacy vault, all application references become tokens. Combining data isolation with tokenization, you get data privacy plus the utility and convenience of storing a form of identity in your logs. With the right permissions, you can detokenize the tokens to retrieve the original sensitive data when your workflows need it.
3. Encrypt During Transit and at Rest
In 2021, DreamHost leaked 814 million records online because of a non-password protected database and unencrypted internal records written to monitoring and file logs. This incident is a good reminder that it’s imperative that you encrypt data during transit and at rest. If your data is encrypted at rest, then even if someone steals your database backup or log file, they’ll need the key to do anything with the data.
Additionally, since web servers often automatically log requests, you need to encrypt data during transit, even between internal systems. This will help prevent encrypted sensitive data from ending up in your logs.
4. Keep PII Out of URLs
It’s common for proxy and web servers to automatically log URL requests. If you have a URL structure like /users/name-of-individual or /users/email, the names and email addresses of your customers are likely to be logged.
To avoid this, you should replace the use of sensitive user identifiers in URLs like names and emails with an arbitrary ID. This could be the row ID of the user, or if you need different URLs to map to different field values you could utilize tokenization here as well.
In the image below, the problematic URLs on the left hand side get transformed into the URLs on the right via tokenization. The token values become the URL identifiers.

If you’re already utilizing the first two best practices in this guide, your application is only storing tokenized data. This means that your application database queries will continue to work against the tokenized identifiers passed in the URL without modification.
5. Redact and Mask Data
Besides tokenization, combining redaction and masking is another effective method to keep sensitive data out of your logs. Some application services may need partial access to data, like the last four digits of a credit card number or social security number (SSN).
Data masking is a one-way irreversible process for protecting sensitive data. A masking method creates a version of the sensitive data that looks structurally similar to the original but hides the most sensitive information contained within a field. Redaction is similar to masking, but hides all of the information contained within a field.
For example, in the image below, first names, last names, and SSNs are masked. The masked values can safely be written to your logs.

There are also many situations where an application service doesn’t need to know even partial information. In this case, the sensitive data should be redacted instead of masked.
6. Data Governance
A data privacy vault isolates sensitive data and prevents copies from being replicated throughout your systems. But locking data away isn’t enough. Real value comes when you can both store and use data securely.
So, while tokenization, masking, and redaction are techniques for using data securely, you still need a way to govern access and control data visibility for various apps and services. This way the information in your logs matches each service’s access to sensitive information.
Data governance is a collection of policies and processes that help assure that data is managed, secured, accurate, audited, and documented. For example, in the image below you can see how the policies set for a specific user role determine which fields are redacted, how data is masked, and how data is tokenized.
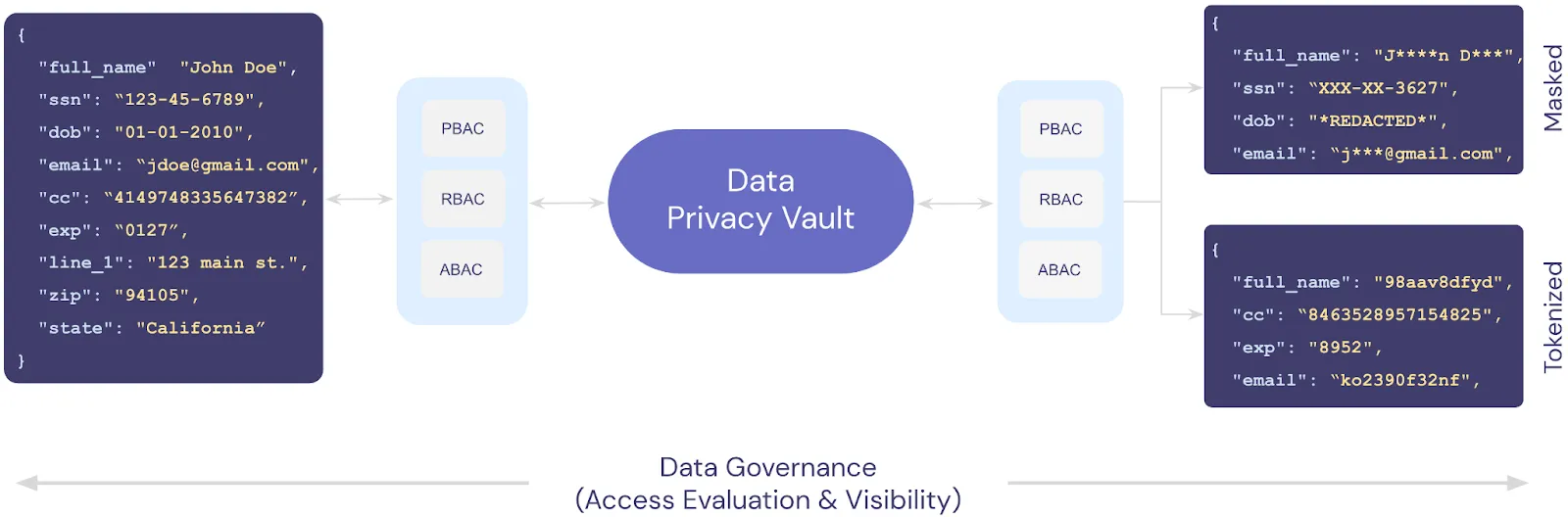
By tightly controlling not only access but how a service can view data, you’re greatly simplifying the mental gymnastics that application developers need to do when thinking about sensitive data and logging. A locked down system prevents mistakes from happening in the first place.
In the next section, we look at a few additional best practices that will further prevent mistakes from occurring.
3 Best Practices for Preventing Mistakes
The best practices above, if followed correctly, will keep sensitive data out of your logs. However, mistakes can happen. For example, a service or engineer could accidentally log raw sensitive data if governance to the data isn’t set up correctly. To mitigate and prevent human error, you should follow the following additional engineering best practices to prevent missteps with sensitive data:
1. Code Reviews
Code reviews are a standard engineering best practice. As part of this process, reviewers should pay attention to log statements and call out any potentially problematic logs. This could also be part of a product launch checklist where someone has to explicitly sign off on having verified that no sensitive data is being logged.
Creating an engineering culture that’s aware of the risk of logging sensitive information will go a long way toward preventing the problem. Making sure sensitive data isn’t logged no longer becomes the sole responsibility of one person, but is a shared responsibility across the entire engineering organization.
2. Structured Logging
With structured logging, your logs are relational data sets, like key/value pairs, rather than just text. Structured logging has the advantage of being more easily searched and analyzed. It can also help with keeping sensitive data out of your logs.
As part of your logging pipeline, you can build in heuristics to check whether any of the data set keys map to known sensitive data fields. If they do, don't write any portion of these datasets to the logs. The heuristics could check against fields like name, email, password, and so on.
This isn’t a perfect system, but does provide some level of automated testing.
3. Automated Alerts
The final step is to create a service that proactively searches existing logs for sensitive data and if found, notifies the team. This might seem like a lot of trouble, but it can help to catch mistakes. Modern systems are large and complex, even if you’re doing all the right things, it’s easy for PII to accidentally slip into a log file.
Final Thoughts
In this article, we presented a total of nine best practices that all companies should follow to prevent the risk of leaking sensitive data through logs. One of the reasons techniques like data isolation, tokenization, encryption, masking, data governance, and so on aren’t always applied in this way is due to the complexity. An application developer is focused on building product features. If logging in a privacy-preserving way is too onerous, it can lose out to other priorities instead of getting the attention that it deserves.
This is why we built Skyflow.
With Skyflow, you get all of the security and privacy-preserving techniques described in this post (plus more) available with just a few lines of code. And it doesn’t just help you keep sensitive data out of your logs – you can also use Skyflow to protect sensitive data in Large Language Models (LLMs), so you can harness the potential of generative AI without sacrificing data privacy.
If you want to try it out, you can sign up for a demo.