
How to De-Identify Unstructured Data in Databricks Using Skyflow
Unstructured data makes up nearly 80-90% of enterprise data, from documents and emails to images and audio files. Yet, despite the massive adoption of data lakes and lakehouse architectures like Databricks, most of this data remains underutilized.
Unstructured data isn’t just difficult to analyze – it’s hard to secure, especially when it contains sensitive information like personally identifiable information (PII), protected health information (PHI), and PCI-regulated content.
At the same time, the explosion of agentic AI and AI-driven analytics means unstructured data is more valuable than ever, powering everything from predictive models to digital healthcare assistants. But tapping into that value requires a privacy-first approach to managing data at scale, ensuring that agentic workflows access only the data they are expressly allowed to access, and nothing more.
In this post, we’ll cover how to use Skyflow’s data privacy vault to detect and de-identify sensitive information in unstructured text inside Databricks, using a simple, reusable function that plugs right into your Databricks workflows.
We’ll also explore how to then safely use unstructured data in Databricks, with Skyflow enabling secure storage, safe data operations, and compliant sharing, all without exposing sensitive information.
>> Watch: How GoodRx Ensures Privacy of Sensitive Data for AI and Analytics with Skyflow & Databricks
Unstructured Data in Databricks
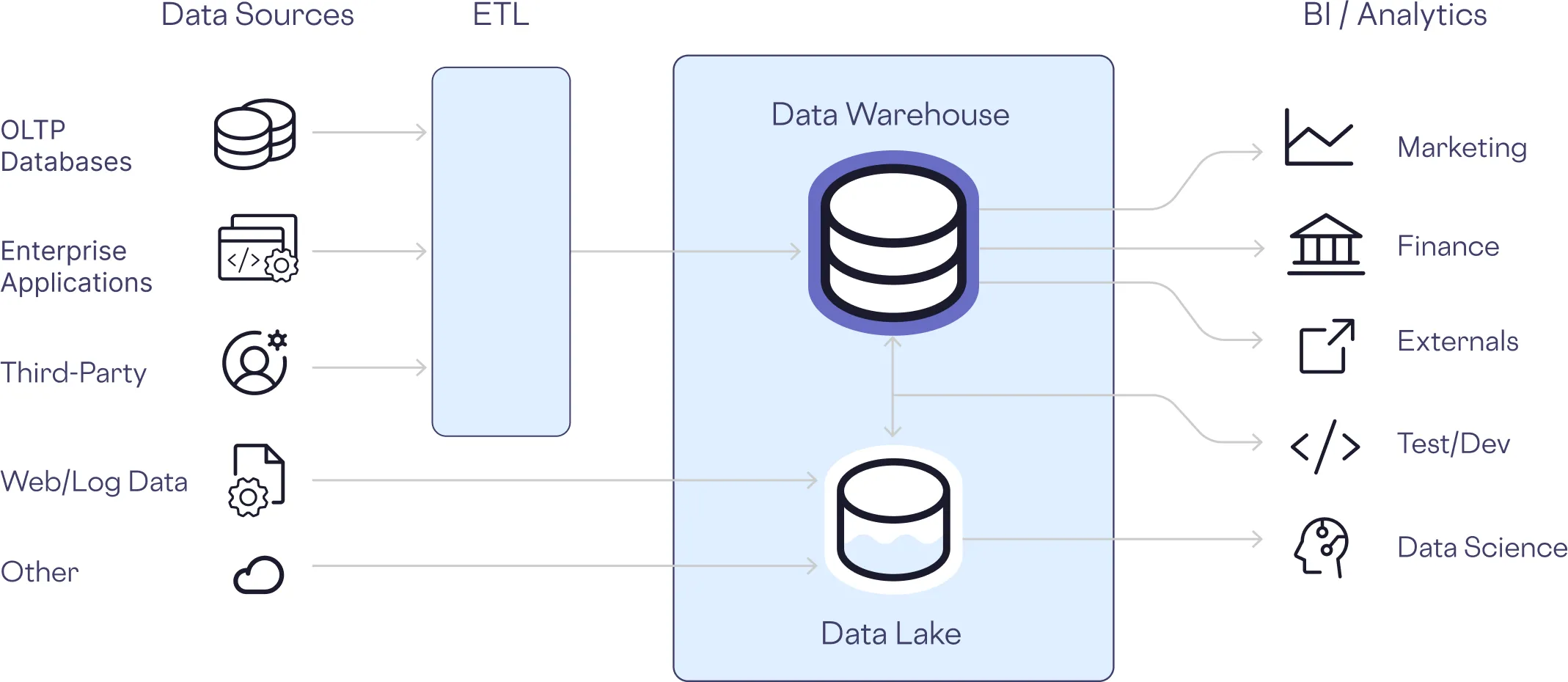
Databricks handles both structured and unstructured data, allowing teams to run advanced analytics and AI models across a broad range of datasets.
But many organizations struggle to make full use of their unstructured data because of the risk of sensitive data leaking through unstructured files. Consider these files, each containing highly sensitive information:
- A scanned passport image stored for KYC contains highly sensitive PII
- A PDF of financials shared for external audit contains PCI and payments data
- Unstructured chat logs that contain sensitive information
Each carries a different risk, and each requires fine-grained protection at the file level, something traditional encryption and perimeter security can’t offer.
Sensitive Data Detection for AI and Analytics
In the video demo below, Skyflow detects PII, PCI, PHI, and other sensitive data, then tokenizes and otherwise redacts sensitive content before it's ingested into Databricks, preserving data utility.
Databricks can access de-identified references or metadata from these files, reducing compliance surface area and preserving analytical utility.
Secure Computation on Unstructured Files via Skyflow Secure Functions
For teams needing to extract data from a file or redact sensitive fields before a file lands in their Databricks workflows, Skyflow Secure Functions allow you to run custom logic like OCR, redaction, or age verification within a secure, compliant execution environment. The original file stays protected; the output file is non-sensitive.
For example, a healthcare company uses Skyflow to extract sensitive medical information from audio files and text files before using those files for AI training, preventing inadvertent leakage of sensitive data.
How to Use Skyflow in Databricks: UDFs and External Functions
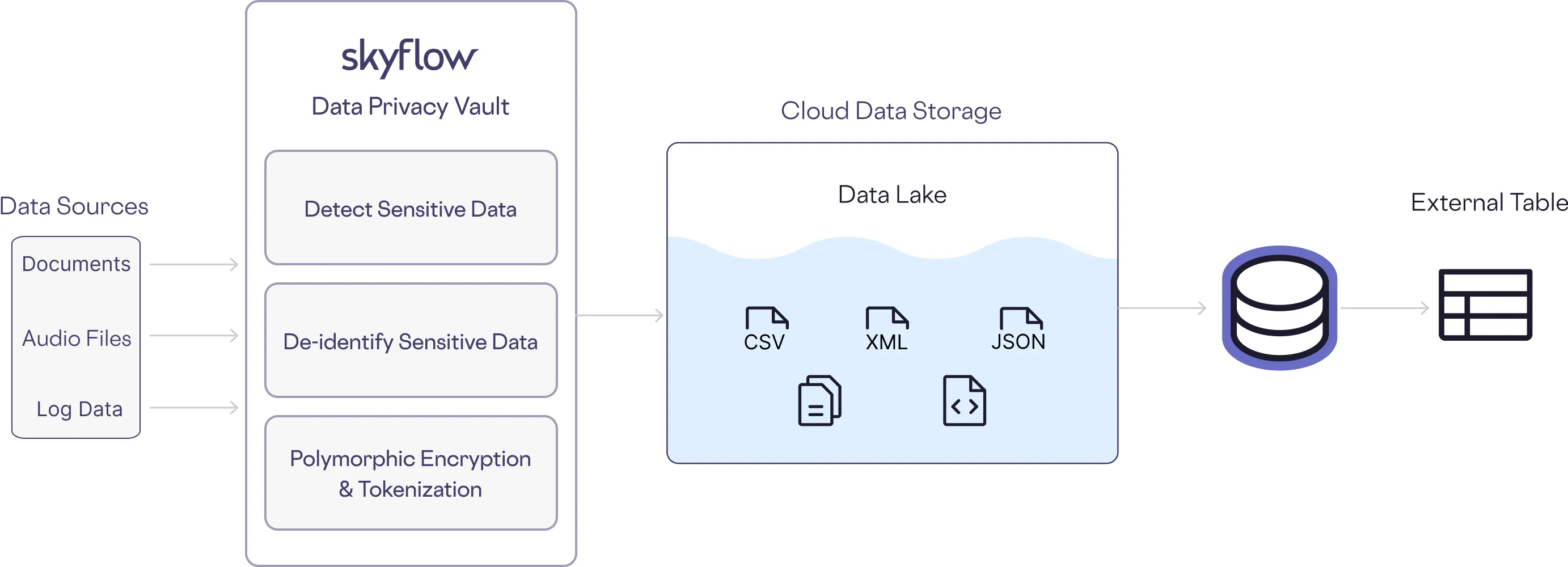
Skyflow’s detect and deidentify functions can be used throughout the Databricks environment in ETL pipelines and Delta Live Tables, as as a preprocessing step before LLM or AI model input, in agentic apps and chatbots to protect user-entered text, and in dashboards and reports to safely summarize trends without exposing PII.
Because the function runs inline in SQL, it’s easy to insert into existing Databricks architecture without major rewrites.
Skyflow integrates with Databricks via external functions or secure UDFs. These functions:
- Automatically tokenize sensitive data on ingestion before queries are run.
- Allow selective re-identification only for privileged users, providing an additional level of governance over existing data.
These functions are available to users through Databricks Unity Catalog and can be used throughout the Databricks platform, including in AI agents, data analysis, queries, notebooks, and more.
Privacy-First AI and Analytics in Databricks
Skyflow makes it easy to isolate and protect sensitive data while preserving usability. With this Databricks function, you can bring privacy-by-design directly into your unstructured data workflows, helping companies stay compliant, reduce risk, and unlock new use cases for AI.
Unstructured data is central to next-gen analytics, AI, and customer experience, but it’s also a regulatory minefield.
Skyflow embeds a privacy layer directly into a team’s Databricks architecture, providing enhanced privacy and security without disrupting data pipelines:
- Collect and store files without risk: Data is protected and isolated through secure collection through the applications via front-end SDKs (Skyflow Elements)
- Full file governance: manage who can access, for how long, and under what conditions
- Detect and redact sensitive content before AI training or analytics using file-level redaction, detection, de-identification, tokenization, and polymorphic encryption
- Secure data with region-specific storage to comply with data residency and sovereignty requirements (GDPR, DPDP, etc.)
With Skyflow and Databricks together, enterprises can unlock the value of unstructured data and secure it for use with their agentic workflows.
Get a demo of Skyflow for Databricks.