
How to Secure Your Warehouse Against Data Breaches
We collect data into warehouses and lakes to gain insights that improve the customer experience, our products, and ROI. To achieve this, our marketing, analytics, operations, and data science teams need access to this data – but storing sensitive customer information like PII in our analytics stores exposes us to the risk of a data breach, unauthorized access, and more.
The simplest way to secure your warehouse and minimize the risk of data breaches is to avoid storing customer PII there altogether. However, this approach weakens the capabilities of our data and analytics platforms.
So, how can we protect our warehouse and analytics pipelines from breaches by excluding PII, yet maintain the full functionality our teams need to perform their jobs effectively?
In this post, we explain how you can use Skyflow with Snowflake or other cloud-based warehouses and analytics data stores to transform sensitive data into non-sensitive data that still keeps the data useful. This removes PII exposure risks while allowing analytical and machine learning operations to work as expected.
The Data Teams PII Problem
Our data teams are often forced to act as the "data police," managing access to the warehouse and data lake while trying to limit permissions. This task quickly becomes unmanageable, leading to an overwhelming number of access requests and potential accidents where someone is granted excessive permissions, risking unintentional PII exposure.
Vast amounts of data from multiple sources is aggregated by the data team into platforms like Snowflake and Databricks. This aggregated data is then used by analysts, data scientists, and other teams. Unlike transactional databases, which only the application itself accesses, analytics stores such as data warehouses are designed for use by our internal teams.
We can’t simply lock the data up and throw away the key. We need to grant access.
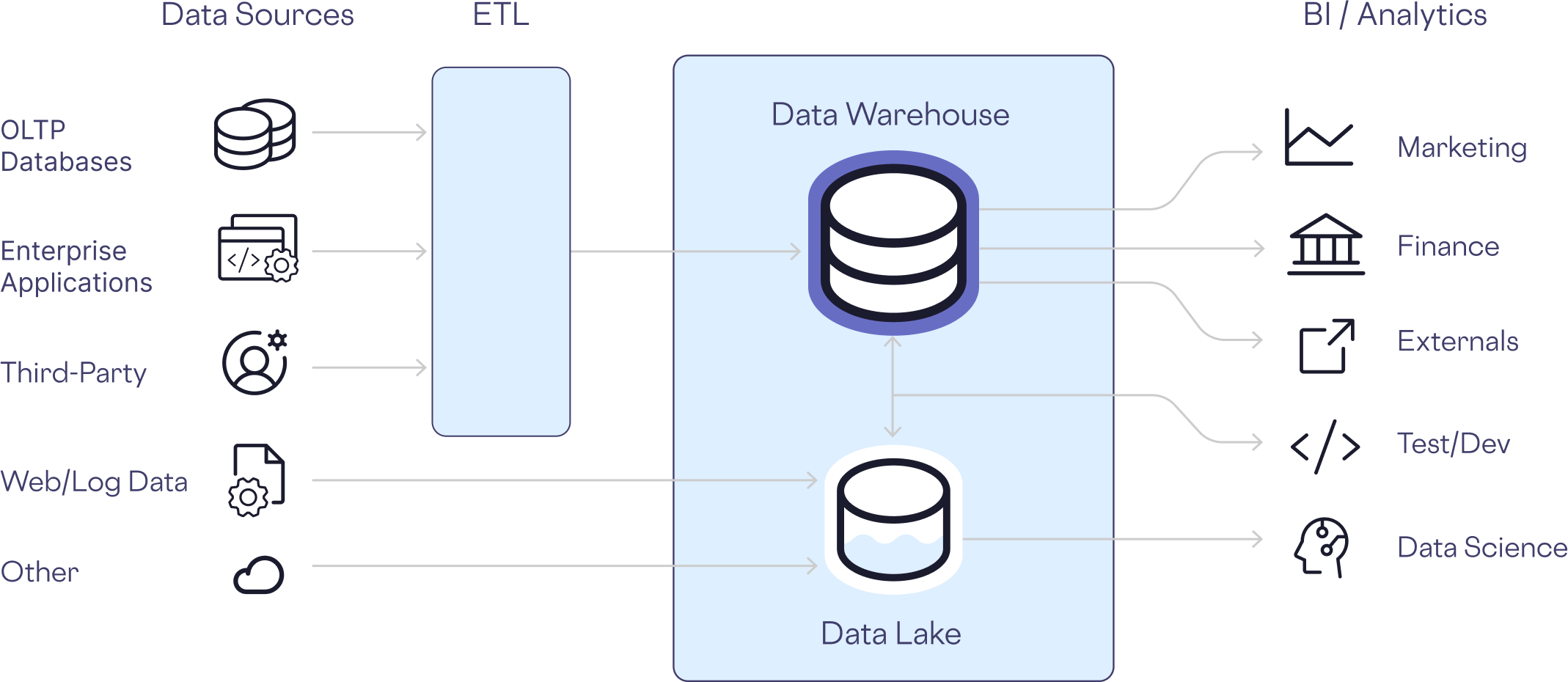
However, as more people are given access, that creates more weak points in the security of the data. Breaches often exploit the people who have legitimate access.
So how do we solve this problem?
The key to solving this problem is to treat PII differently from other data forms by isolating it, protecting it, and governing access in a fundamentally new way.
Re-thinking Our PII Technology Stack
Twenty years ago, it was not uncommon to store user passwords in our databases in plaintext. Eventually, we realized that not only was this not safe, but we didn't actually need the original password to satisfy the one business requirement we have with a password, which is to know whether it exists or not. We can satisfy this requirement while also destroying the original password through salting and hashing.
Over the past decade, we've developed specialized technologies for handling different types of sensitive data, such as encryption keys, secrets, and passwords. The handling requirements for these data types are vastly different from those for non-sensitive data. For instance, encryption keys and secrets need regular rotation, very restricted access (often limited to internal systems), and rigorous monitoring and auditing.
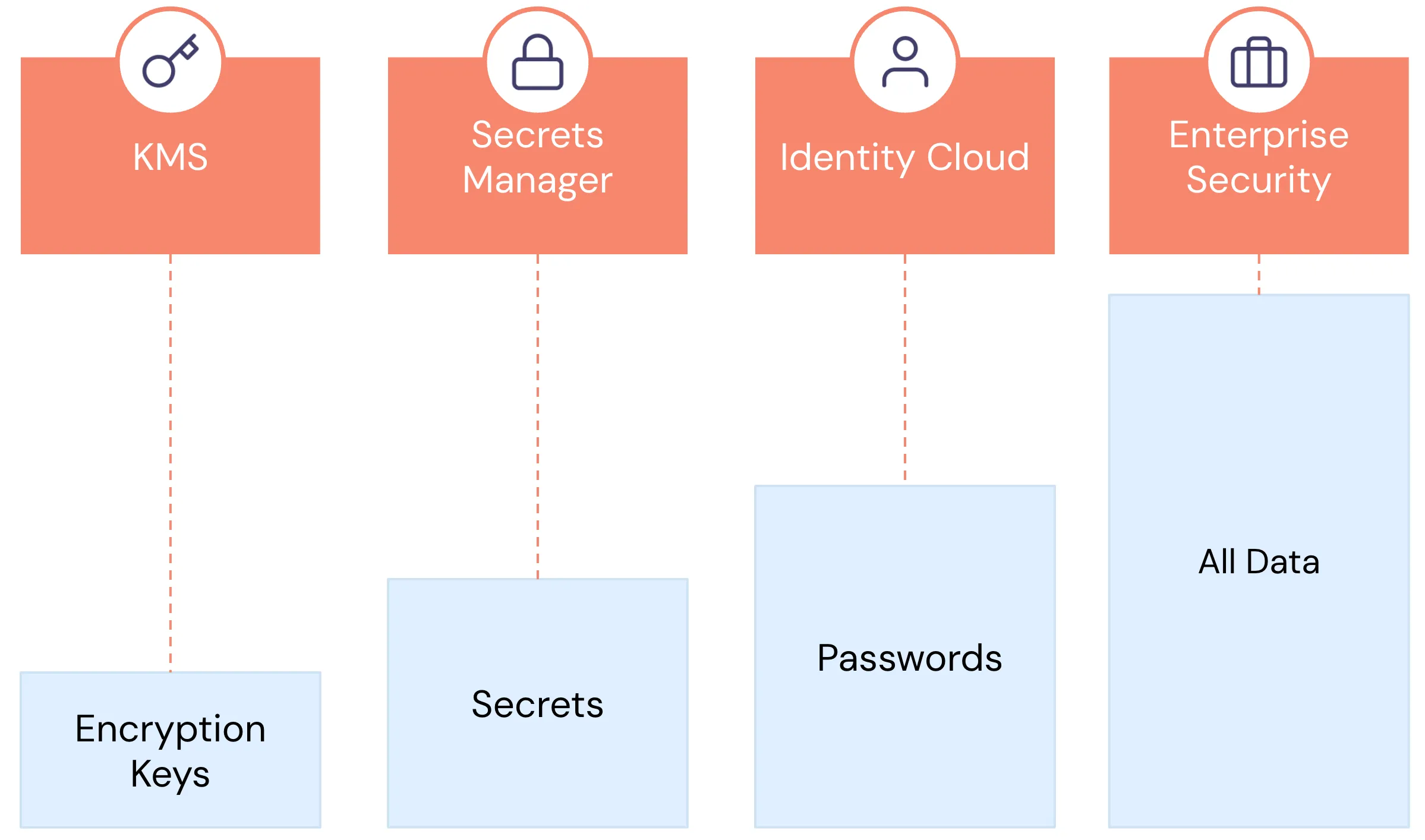
Similarly, sensitive customer data, like PII, is fundamentally different from non-sensitive application data. It’s highly regulated, sometimes has regional restrictions about where it must be stored, access needs to be closely monitored, leaking PII carries significant consequences for our customers and business, and different people and services need different types of access. For example, customer support might need the last four digits of a customer’s Social Security Number (SSN) while your KYC vendor might need the entire value, and most other users and services shouldn’t have access at all.
In recent years, companies like Apple, Google, and Netflix recognized this problem, pioneering a technology known as a zero-trust data privacy vault. In 2022, the IEEE recognized this approach as the future of “privacy by engineering.”
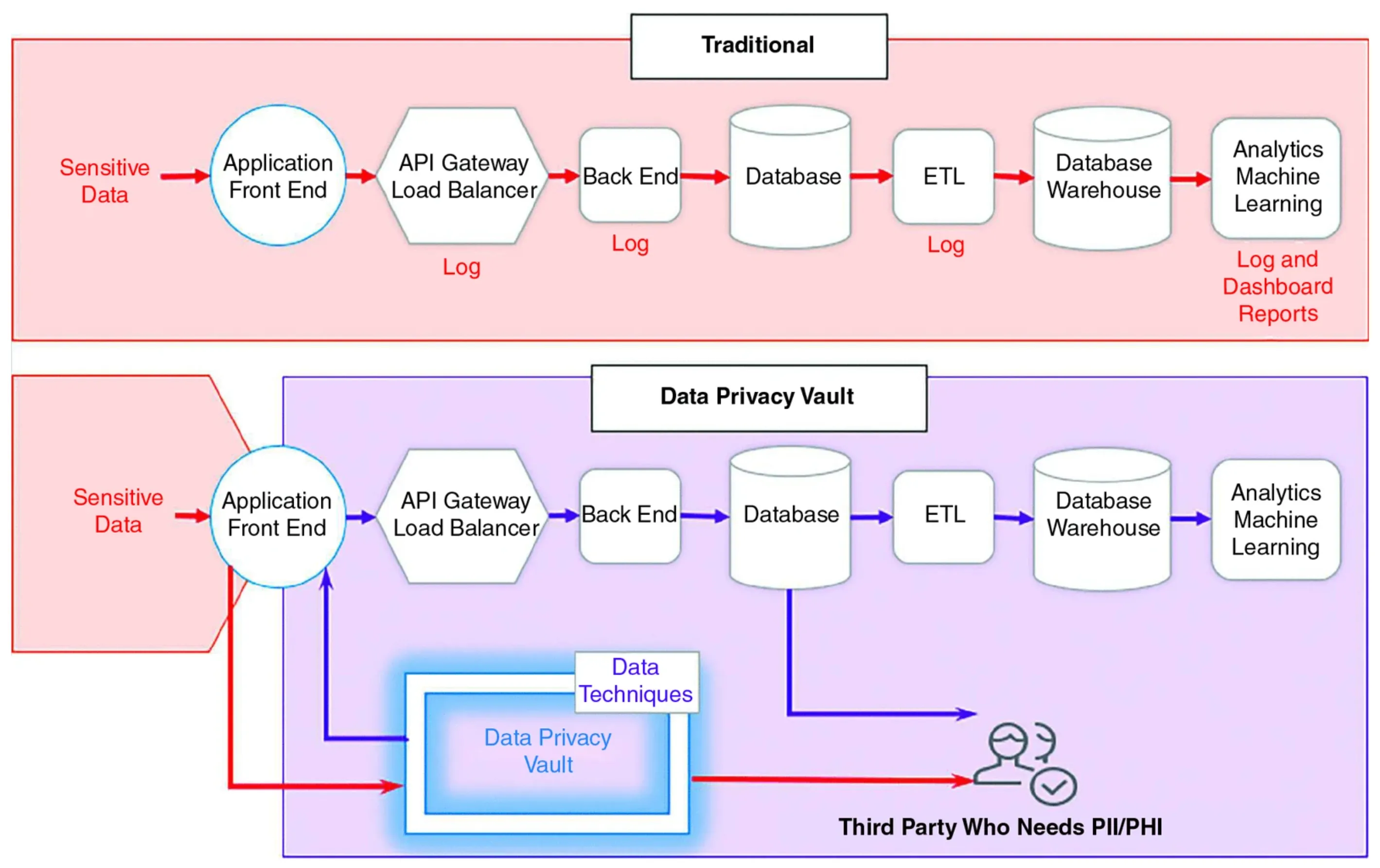
The idea behind the data privacy vault architecture is to isolate, protect, and govern access to sensitive customer data, replacing existing references in your downstream services with non-sensitive references in the form of tokens. A token is an obfuscated string that represents other, more sensitive data. The de-identified tokens carry no sensitive information, so even if your warehouse is compromised through a leaked employee credential, the warehouse doesn’t contain any sensitive PII.
As an example of the value of data anonymization, in 2019, Capital One suffered a data breach. There were 100 million affected customers in the US, but because Capital One was protecting some of their customer data through tokenization, only 1% of customer SSNs were compromised. Other sensitive data was encrypted, but the hackers were able to decrypt the data by harvesting the encryption key by compromising an IAM role in AWS.
Let’s take a deeper look at how this works.
Anonymizing PII but Keeping it Useful
When we think about keeping data secure, we naturally think about encryption. Assuming you choose an appropriate encryption algorithm, work through your encryption key management challenges, and key rotation, as part of this process, you’ve likely broken many existing workflows.
Your customer support team probably needs to be able to use the last four digits of a customer’s SSN, which they no longer have access to. Your data model might assume a customer’s date of birth, phone number, and email has a specific string format, which is now broken. And all your carefully crafted search indices are broken.
So while it’s the right approach to replace sensitive data with something else, you need the something else to solve these new problems as well.
While hashing works for passwords, it doesn’t immediately solve all our PII problems. If we destroy the original customer data, like someone’s SSN through salting and hashing, then we can’t show our customer support team the last four digits. We won’t be able to share a customer’s credit card information with our payment service provider to collect a payment. So we need a more advanced solution.
Isolate, Protect, and Govern Access to Sensitive Customer Data
Skyflow Data Privacy Vault isolates, protects, and governs access to sensitive customer data. This data could be structured or unstructured data. Sensitive data is transformed by the vault, while non-exploitable tokens that serve as references to the sensitive data can be stored in traditional cloud storage or used in data warehouses.
To keep the data useful for analytics, machine learning, and other workloads, Skyflow has developed proprietary privacy-enhancing encryption and tokenization technologies known as polymorphic encryption and polymorphic tokenization.
Polymorphic Encryption and Polymorphic Tokenization
Data stored within Skyflow is polymorphically encrypted within the vault, using either keys provided and managed by Skyflow or those designated by the customer. This encryption method keeps the data secure while still useful, enabling a variety of encrypted operations. This guarantees that while your customer support team can access the last four digits of a customer SSN, they have no access to the rest of the SSN. Or your analytics team can run queries against the customers area codes but not have access to any individual customer’s full phone number.
To adhere to data residency regulations, the encrypted data is securely stored in geographically appropriate regions, enhancing compliance and regulatory adherence.
Additionally, Skyflow’s polymorphic tokenization lets you anonymize the sensitive data, taking your warehouse out of data security scope, while also keeping the data useful for analytical purposes.
Below is an example of some of the polymorphic tokenization options in Skyflow and how they can be used in your analytics store.
Random Tokens: The original PII is replaced with a randomly generated value that does not reveal any information about the original data. The same input value will generate different output values. This is commonly used when there’s only one possible input per customer, like a government ID or credit card number
Consistent Tokens: With this approach, the same input value always maps to the same token value. This approach can be reliably used for search, joins, group bys, counts, and other operations as non-sensitive stand-ins for the original value.
For example, your marketing team can still run queries to measure product engagement by customer cohort without needing access to any individual customer’s PII.
Format-preserving Tokens: Retains the format of the original data, for example, an email can still look like an email or a phone number like a phone number. This is important in the data world for maintaining schema expectations. Existing sensitive data can be swapped for format-preserving stand-ins without the need to update the schema.
Context-preserving Tokens: A token that maintains the specific context of the original data. With LLM training, unstructured data containing PII can be detected and replaced with context-preserving tokens that maintain the entity information. For example, “John lives in San Francisco” would become “NAME_1 lives in LOCATION_1”.
Once secured, operations can be conducted on the data, all of which strictly adhere to the governance policies set within the vault.
Fine-grained Access Control
Governance policies establish fine-grained access controls, allowing for meticulous control over data access. The granular control empowers organizations to precisely dictate who has access to specific data, providing a robust and secure framework for data management.
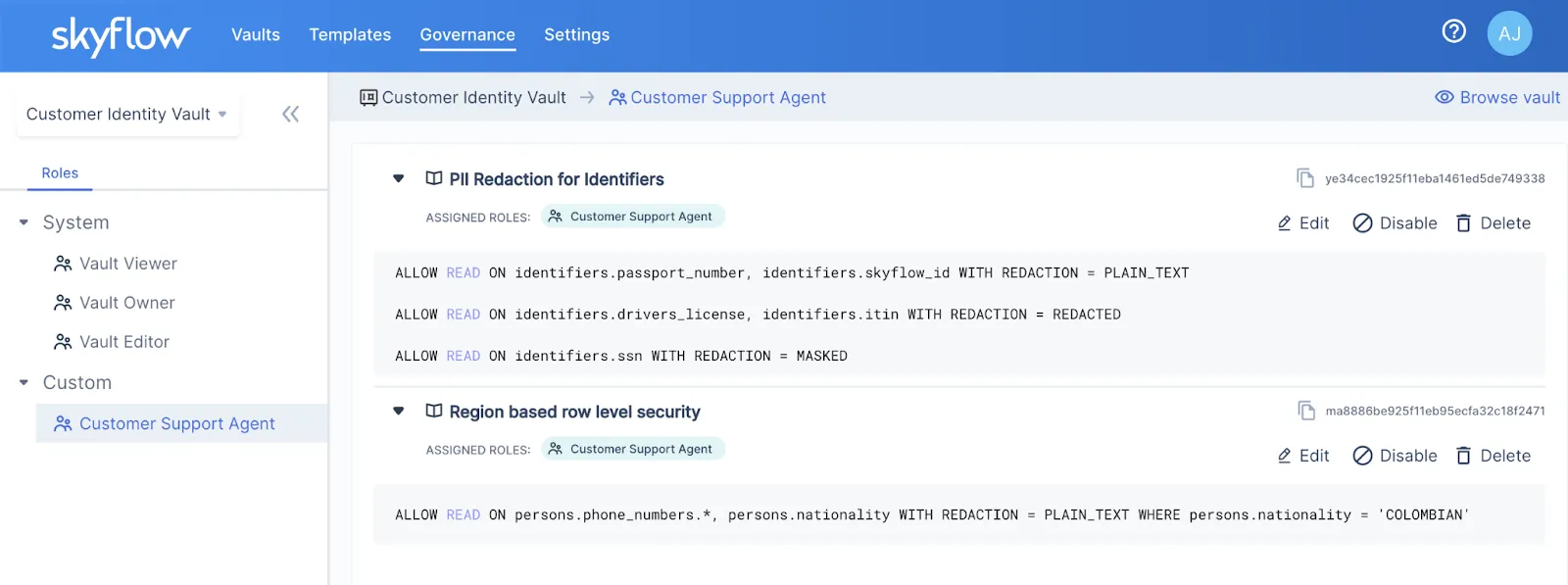
You have a range of options to use the data stored within the vault, whether it's structured or unstructured:
- Access and Retrieval: Seamlessly view or retrieve information directly from the vault, providing quick and efficient access to valuable data.
- Secure Data Sharing: Implement secure integrations to share data from the vault with third parties. This secure sharing is particularly crucial for completing business workflows like KYC or payments.
- Custom Logic Execution: Run custom logic on the data within the vault, enabling customers to derive specific insights tailored to their unique requirements.
- De-identification Processes: De-identify data, whether structured or unstructured, including text, audio, images, and videos. This process ensures privacy and security, allowing the storage or transmission of de-identified data to third parties for processing, reporting, or even contributing to the training and fine-tuning of Language Model Models (LLMs).
De-risking the Modern Data Stack
Using a combination of privacy-enhancing features provided out of the box with a Skyflow vault, we can create an analytics pipeline that’s safe from data breaches and bad actors.
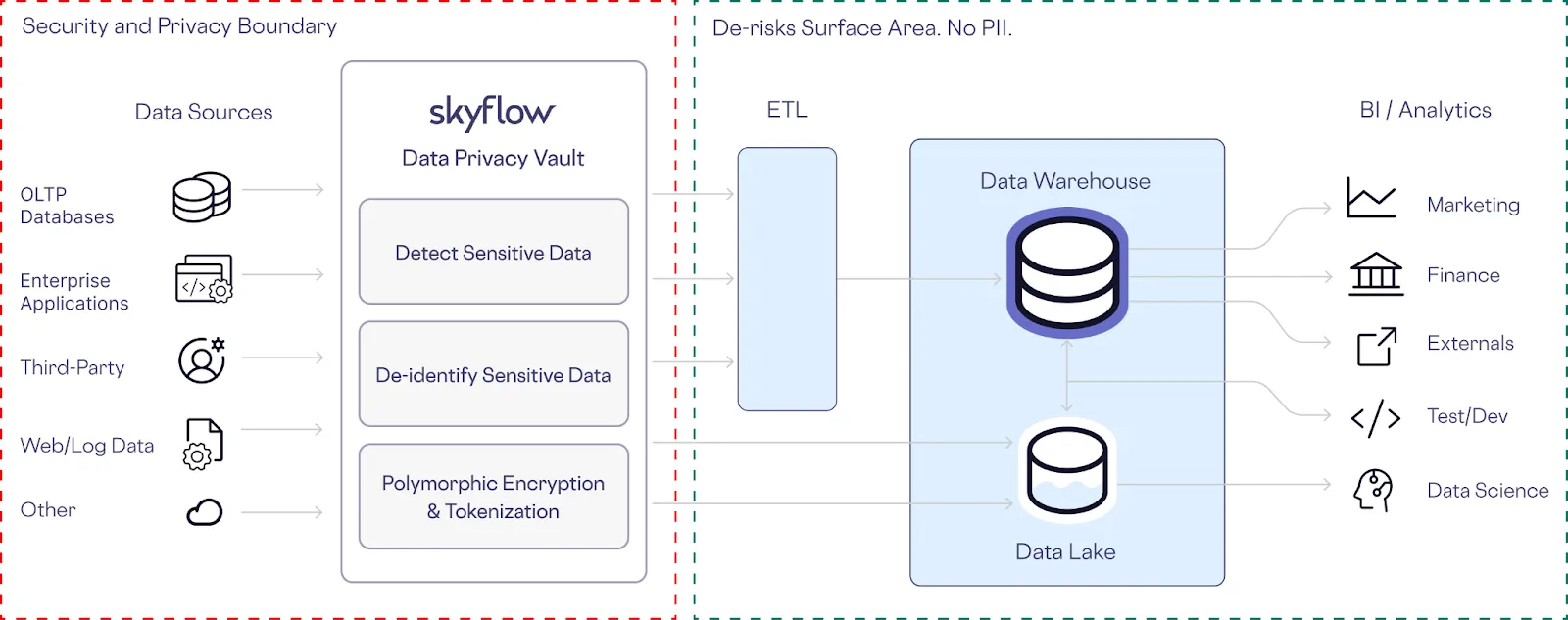
In this architecture, Skyflow serves as a crucial intermediary, transforming sensitive data into non-sensitive data at the head of ETL pipeline from both structured and unstructured sources.
This removes customer-specific personal information from the datasets used by downstream systems like your warehouse and data lake.
By replacing the original data with polymorphically generated tokens, all the stakeholders of your warehouse or lake can continue to do their work.
This also helps take your data teams out of the business of being the data police. You can open up internal access and feel confident to load even more data without the risk of PII exposure.
Even if the worst case scenario does take place and your credentials are compromised, there’s no customer data stored directly in your analytics stack.
Key Takeaways
With so many high profile data breaches over the past two years, protecting sensitive customer information while maintaining its usability is absolutely crucial.
Here are the key takeaways on how Skyflow helps achieve this balance:
Data Security Risk: Storing sensitive customer information (PII) in data warehouses, despite security measures, poses significant risks if access is compromised. Encryption and security perimeters can’t help you when an attacker has access through valid credentials.
To solve this, Skyflow integrates with Snowflake and other data platforms to transform sensitive data into non-sensitive data, reducing PII exposure while maintaining usability for analytics and machine learning.
Polymorphic Encryption and Polymorphic Tokenization: These technologies allow for secure yet functional data handling, enabling operations like querying and analytics without exposing sensitive information.
Fine-grained Access Control: Governance policies and fine-grained access controls ensure only authorized access to specific data, enhancing security and compliance.
De-risking Data Pipelines: By transforming sensitive data at the start of ETL pipelines, Skyflow removes PII from downstream systems, allowing broader internal access without compromising data security.
If you’re interested in learning more, register for a demo today.