
Advanced Techniques for De-Identifying PII and Healthcare Data
Ensuring the privacy and security of patient data and Personally Identifiable Information (PII) is a top priority for any healthcare or digital health company. De-identification of PII is essential for reducing the risk of a data breach, protecting patient privacy, and enabling secure data sharing for research and analytics.
In this post, we explore the risk of PII exposure, importance of data de-identification, outline effective methods, and highlight how Skyflow’s advanced techniques like polymorphic encryption and tokenization preserve existing workflows while securing sensitive data.
Risks and Consequences of Data Breaches
Data breaches in the healthcare sector have become alarmingly frequent, exposing sensitive patient information and leading to severe financial and reputational damage. Healthcare companies often have a large amount of valuable patient/customer data, making them a prime target for cybercriminals. Understanding the real-world impact of these breaches underscores the critical importance of robust data protection measures.
For example, in 2015, Anthem Inc. suffered a massive data breach. The breach exposed the personal information of nearly 79 million individuals, including names, birth dates, social security numbers, and medical IDs. Anthem ended up paying a record $16 million to settle potential HIPAA violations.
More recently, UnitedHealth-owned Change Healthcare suffered a data breach that likely impacts one-third of Americans. The attacker stole up to 4TBs of data including personal information, payment details, and insurance information. UnitedHealth has said that the attack on Change Healthcare cost it $872 million.
The financial penalties for data breaches extend beyond settlements. In the U.S., organizations must follow various data privacy laws, including the federal Health Insurance Portability and Accountability Act (HIPAA), which imposes fines up to $1.5 million per violation per year, as well as state-level laws like the California Privacy Rights Act (CPRA). Breaking these regulations not only leads to hefty fines but also requires expensive corrective action and results in being listed on the public "HIPAA Wall of Shame." Additionally, the FTC recently finalized new changes to their Health Breach Notification Rule, which defines rules for health-related applications not covered by HIPAA.
In Europe, the General Data Protection Regulation (GDPR) enforces stricter penalties. Companies can face fines up to €20 million or 4% of their annual global turnover, whichever is higher, if they fail to protect patient data properly. This underscores the critical need for effective data protection measures.
Trust and Reputation Impact of a Breach
The impact of data breaches is not limited to financial penalties; they also inflict long-term damage on an organization's reputation. When patients' sensitive information is exposed, trust in the healthtech company diminishes.
This loss of trust can have far-reaching consequences:
- Loss of Trust: Patients expect their personal information to be protected. A breach shatters this trust, leading to doubts about the provider's ability to keep data secure.
- Customer Attrition: Distrust and dissatisfaction can lead patients to seek alternative solutions. This attrition can have a lasting impact on the organization's customer base and revenue.
Ensuring best-in-class data security and privacy measures is crucial for healthcare organizations to protect patient PII, comply with regulations, and maintain their reputation in a competitive market. Organizations that excel in establishing customer trust are also more likely to experience revenue and EBITA growth of at least 10 percent.
Leaders in the space have already figured out how to help prevent the risk of PII exposure using techniques like data de-identification. Let’s take a look at how this works.
What is De-Identification?
De-identification is the process of removing or obscuring personal identifiers from data sets to prevent the re-identification of individuals. In the context of healthcare, this involves stripping patient data of PII such as names, social security numbers, and other unique identifiers.
Why is De-Identification Important?
De-identification is crucial for several reasons:
- Privacy and Compliance: Protecting patient privacy is mandated by laws such as the Health Insurance Portability and Accountability Act (HIPAA) in the United States and the General Data Protection Regulation (GDPR) in Europe. Non-compliance can result in significant fines and legal consequences.
- Data Sharing and Research: De-identified data can be shared more freely among researchers and organizations, facilitating advancements in medical research and public health without compromising patient privacy.
- Privacy-safe Analytics and AI: With modern de-identification techniques, analytics and AI workflows can continue to work as intended without the risk of PII exposure to your analytics and data science teams.
- Trust and Ethical Responsibility: Ensuring patient data privacy fosters trust between patients and healthcare providers. Ethical management of data is paramount in maintaining this trust.
By leveraging de-identification methods, healthcare organizations can significantly reduce the risk of data breaches and the severe consequences that accompany them, ensuring compliance, maintaining trust, and protecting sensitive patient information.
Methods for De-Identification
There are several methods to de-identify patient data:
- Anonymization: Completely removing or obfuscating all identifying information.
- Pseudonymization: Replacing private identifiers with fake identifiers or pseudonyms. This method allows data to be re-identified if necessary.
- Aggregation: Combining data in such a way that individual entries are indistinguishable, useful for statistical analysis.
- Data Masking: Masking sensitive data elements to prevent unauthorized access.
In the next section, we’ll show how Skyflow supports various forms of data de-identification to support any potential use case.
De-identifying Sensitive Data with Skyflow
Skyflow is a data privacy vault that uses advanced techniques like polymorphic encryption and tokenization to de-identify sensitive data while preserving its utility for analytics and AI workflows.
From a security perspective, the ideal scenario is that we de-identify data as early in the lifecycle as possible and re-identify as late as possible. This helps de-risk the most surface area as no downstream services will see PII, instead they’ll work with de-identified token values.
For example, in the image below, data is being de-identified at the application front end. PII is transformed into de-identified values potentially preserving the format of the original data so that an email still looks like an email but isn’t the original value. De-identified token values can be consistently or randomly generated, depending on your use case.
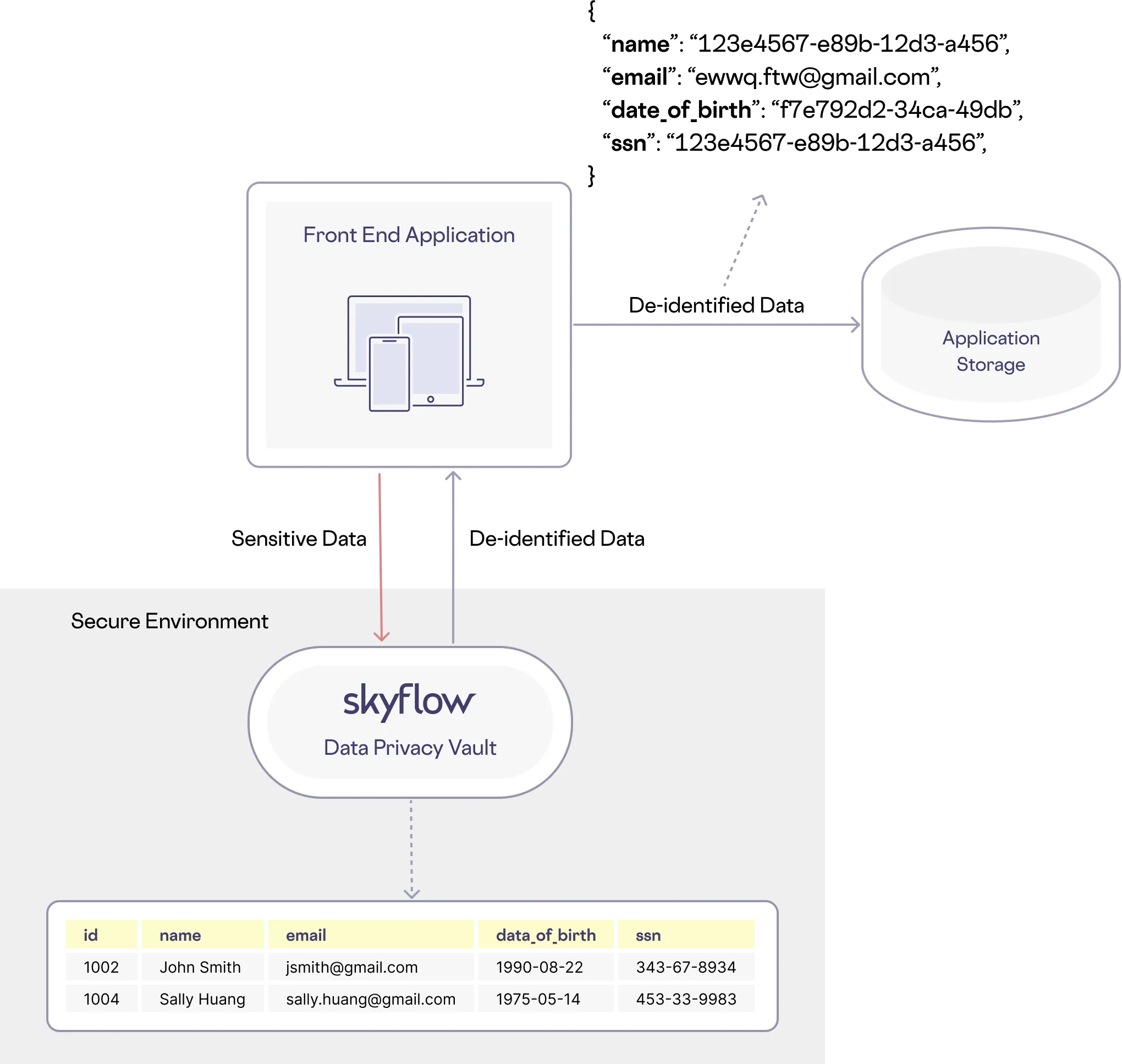
A Skyflow vault can be plugged in anywhere in your stack, from your front end is just one example.
Polymorphic Encryption
Polymorphic encryption allows for data to be encrypted in a manner that enables specific operations to be performed on the encrypted data without needing decryption. This is particularly useful for:
- Maintaining Data Utility: Analytical operations can be conducted on encrypted and de-identified data, preserving its usefulness while keeping it secure.
- Selective Encryption: Different parts of the data can be encrypted using different keys, allowing for fine-grained access control. This means that an analyst could have access to the area code of a phone number or state of an address without having access to everything.
Tokenization
Tokenization involves replacing sensitive data elements with non-sensitive equivalents (tokens) that have no exploitable value outside the specific context. Skyflow's tokenization preserves the format and structure of the original data, making it seamless to integrate with existing workflows and systems.
Data Masking
Data masking is another critical feature supported by Skyflow and is needed to support many digital health use cases. It involves hiding or obscuring specific data to protect it from unauthorized access while maintaining its utility for analytics and other operations, like revealing the last four digits of an SSN to a customer support agent for customer validation.
Skyflow supports masking defaults for most forms of PII, but the masking functionality is very flexible and can be configured to support any application-specific masking rules. For example, in the image below, the “email_id” column has a masking rule that preserves the first character and last character of the local address and preserves the domain, all other characters are replaced by the * character.
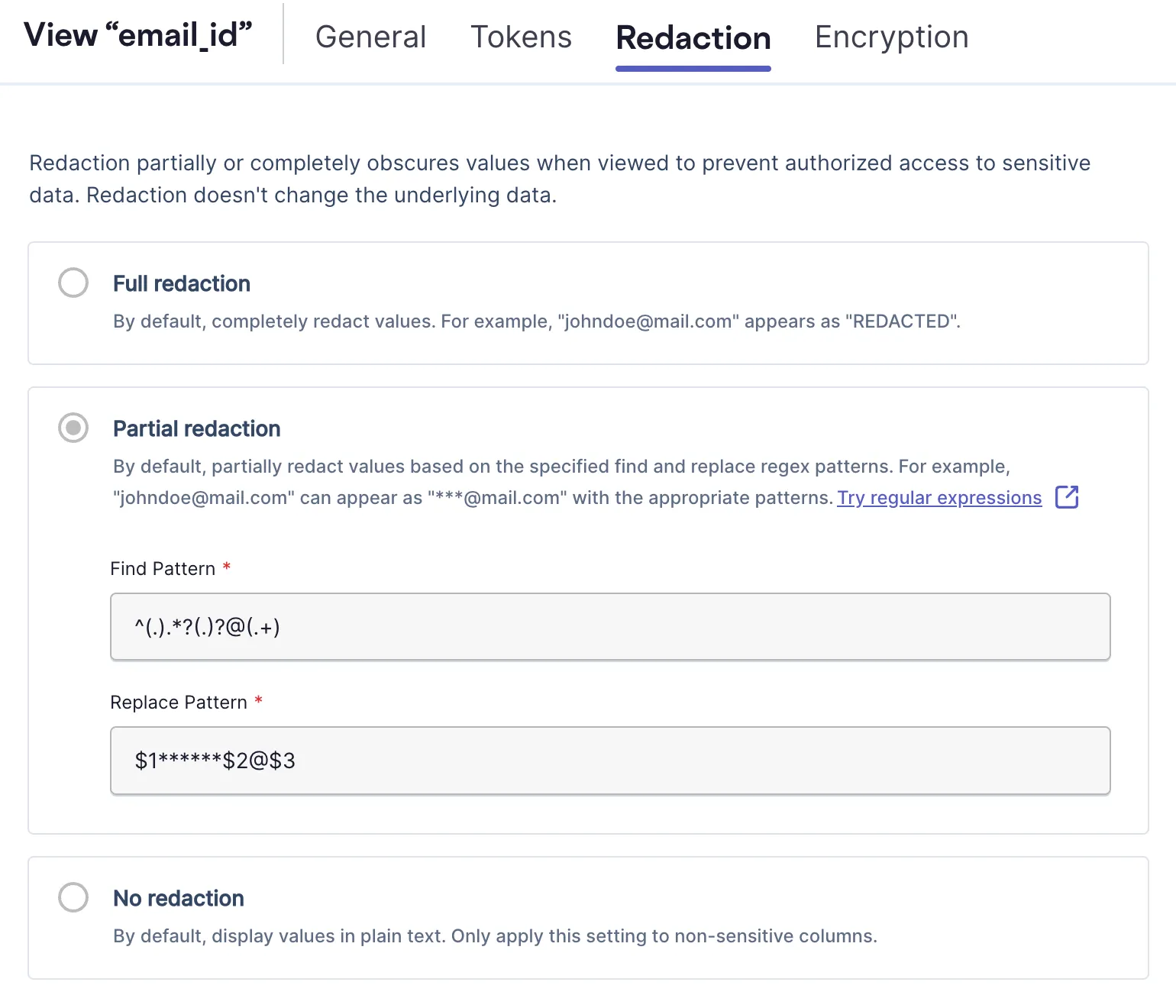
By leveraging Skyflow’s data masking, polymorphic encryption, and tokenization, healthcare organizations can securely de-identify PII, ensuring compliance, protecting patient privacy, and maintaining the integrity and utility of their data for analytics and AI applications.
The combination of these approaches also drastically reduce the risk of PII exposure. PII isn’t duplicated all over the tech stack and instead is isolated and protected within your data privacy vault. Access is tightly controlled through a zero-trust model with fine-grained access control. Raw PII isn't needed for analytics and AI workflows, just a representation of the data via the de-identified values.
Example Use Cases
A leading US-based healthcare startup focused on simplifying access to healthcare services and reducing costs associated with healthcare delivery collects patient and payment data. Due to HIPAA and PCI DSS, collecting, managing, and processing patient and payment data is challenging.
This data must be handled with care across their entire tech stack, including their CRM, marketing automation tools, and all data systems.
Skyflow helps by providing a HIPAA and PCI DSS-compliant shared service that transforms sensitive customer data into de-identified data. The de-identified data can be safely shared across all systems. The compliance scope is greatly reduced across the stack, and analytical operations continue to work.
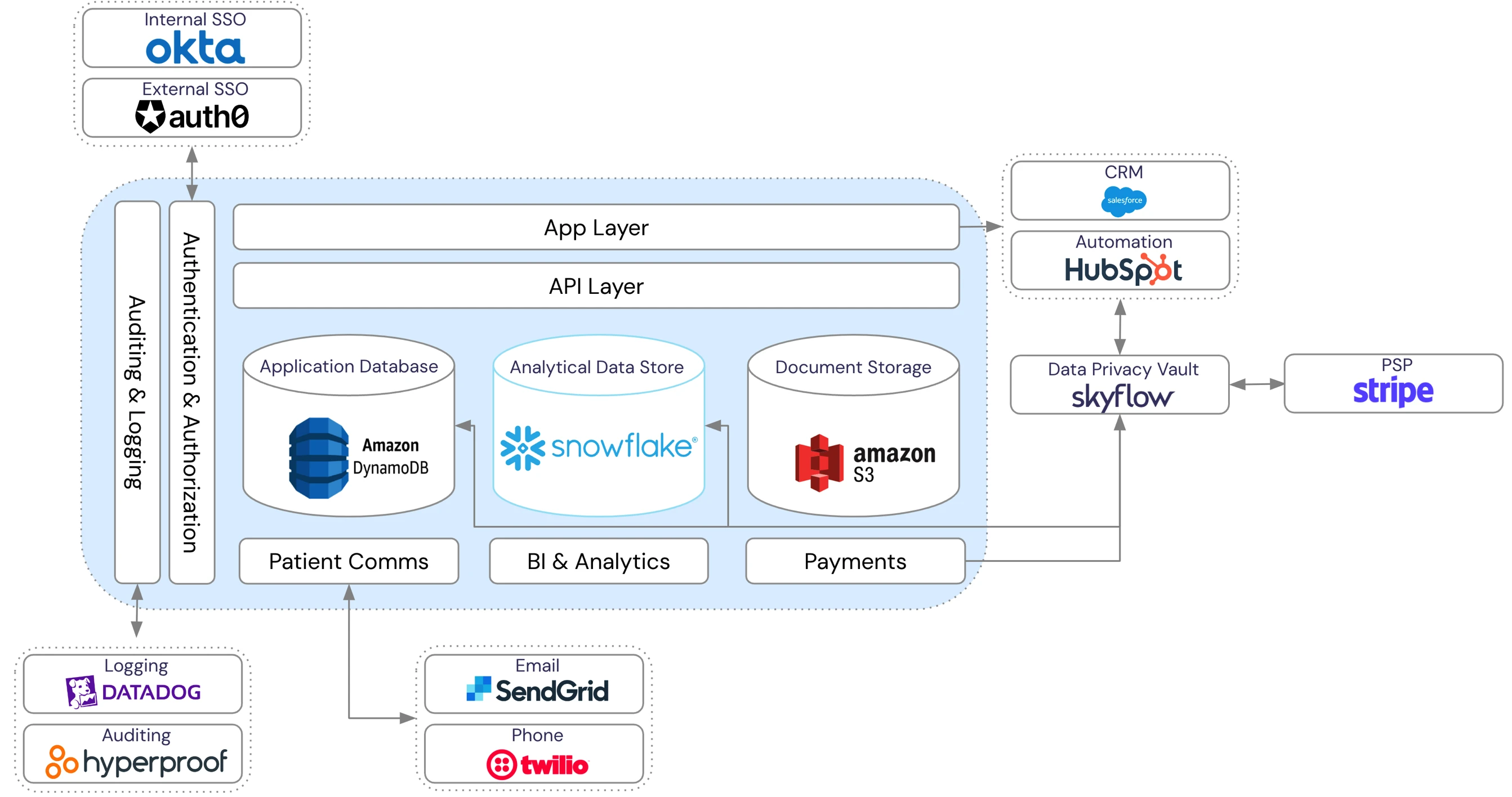
In the above image, no sensitive data is stored within the data stores, CRM, and Hubspot, only de-identified data. When re-identification is needed, for example with sending a payment through Stripe, Skyflow acts as a proxy service to Stripe, securely sharing credit card data.
With analytics, queries work with de-identified values but if re-identification is needed for reporting or BI, controlled access to the vault is supported to re-identify some values based on the policies defined.
Preserving Workflows for Analytics and AI
Using Skyflow's de-identification methods allows digital health organizations to maintain their analytical and AI capabilities without compromising data security.
Here’s how:
- Seamless Integration: Skyflow’s API-based data privacy vaults integrate easily with existing data workflows, ensuring minimal disruption.
- Data Integrity: Tokenization preserves data format and structure, ensuring that systems relying on specific data schemas continue to function correctly.
- Advanced Analytics: Polymorphic encryption and tokenization allows for complex analytical operations on encrypted and de-identified data, enabling organizations to derive insights without exposing sensitive information.
Regulatory Compliance: By adhering to stringent data protection standards, Skyflow helps organizations comply with relevant regulations, avoiding potential legal issues.
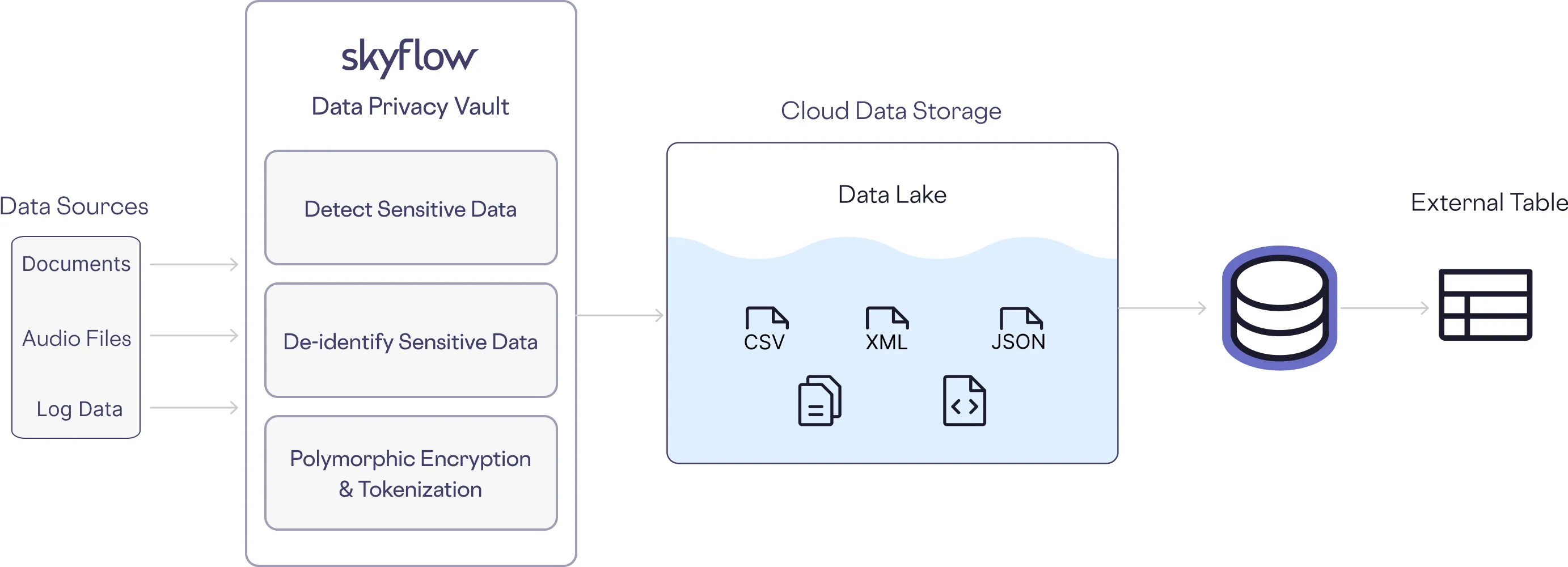
As an example, in the above analytics pipeline, the data sources on the left may contain PII. We want to keep that information out of the data lake and eventual external table used by analysts.
To address this, Skyflow Data Privacy Vault sits at the head of the ETL pipeline, detecting sensitive data and de-identifying it, replacing the PII with non-sensitive references. Only non-sensitive data ends up in the lake.
See this article on preserving privacy during analytics for detailed examples on query operations.
Conclusion
De-identifying patient PII is essential for ensuring privacy, regulatory compliance, and maintaining trust. Skyflow's advanced de-identification techniques, including polymorphic encryption and tokenization, provide solutions that preserve the utility of data for analytics and AI, while keeping the data secure.
For more information on how Skyflow can help with de-identifying health data and PII, visit Skyflow.