
Software Engineering’s Next Great Challenge: Data Privacy
The evolution of our technology stack has been a direct result of creative engineers meeting the needs and demands of their users. However, our technology and product processes are ill-equipped to deal with a new user demand, the demand for privacy. In this post, we explore why existing technology is failing to meet new user demands for privacy and what engineers can do to address this problem.
When I started out building web applications 20+ years ago, the technology that engineers needed to understand and use was relatively simple. You had frontend and backend code often running off the same on premises server. Sometimes even the application’s database was running on the same server.
Over time, we’ve added complexity to this simple infrastructure in order to meet both user and business needs. For example, we:
- Created frontend frameworks like React, Vue, and Angular to improve code reusability, testing, and performance
- Built backend frameworks like Rails, Django, and Node.js, making it easier to build robust scalable applications to meet user demands like faster response times from anywhere in the world
- Developed additional technologies for managing data like NoSQL and SQL stores, and in-memory databases like Memcached
Just as our insatiable appetite to keep improving and reinventing frontends, backends, and data stores has grown, we’ve been hungry to update and improve infrastructure. We’ve moved everything to the cloud and started utilizing technologies like serverless, containers, and autoscaling. We broke up our monoliths into microservices. We’ve invented event streaming technologies like Kafka to meet our ever growing data consumption needs, enabling businesses to process analytics in real-time.
As engineers, we didn’t add all this complexity for the sake of making things more difficult. We’ve built these technologies so that our applications can serve our users better. As consumer demands for speed, powerful UIs, and convenience have increased, we’ve risen to this challenge time and time again.
However, there is a new challenge, a new user demand — and that’s data privacy.
The Demand for Data Privacy
We are long past the days when users didn’t think about the information they give away freely to companies and applications. For example, in the April 2021 iOS 14.5 update, 96% of iPhone users opted out of having their location tracked across apps.
There’s a sea of change happening with regards to consumer demand for privacy. Modern users want to understand why you need the information you’re collecting. And they have questions about what it will be used for, and how they can manage it.
However, it’s extremely challenging to meet this consumer demand with the software design approach and technologies that we are using today. Data privacy isn’t part of our stack or design approach. Addressing privacy after we’ve already been collecting, copying, and possibly logging user data is a nearly impossible task.
Why Our Process and Stack is Failing Us
Let’s explore why our existing product development approach and technologies can’t help us solve user privacy.
Orphaned Data
Historically, we think of orphaned data as a child record that has lost its parent (see image below). More generally, orphaned data encompasses any record where the business no longer knows whether the data is used, what it’s used for, or where it comes from.
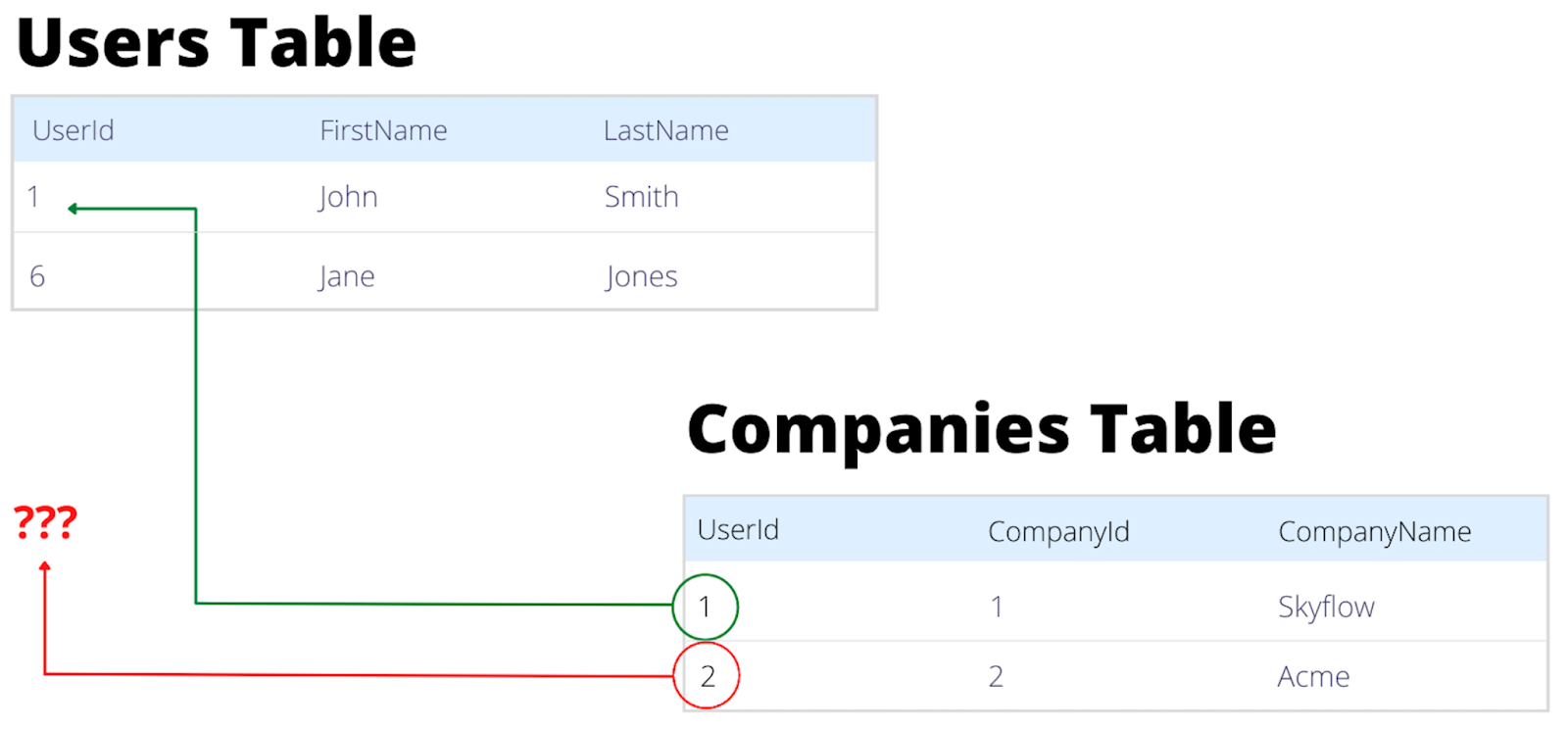
Products don’t start out with orphaned data. It happens over time as the application and system architecture evolves to meet increased user and business demands. As demands increase, data gets copied and moved to support new infrastructure and product offerings. Perhaps Kafka was introduced to support the business’s data pipeline and BI tools that are used by their data science team.
Additionally, the company is evolving, and engineers are coming and going. The company is moving too fast to meet customer demands and keep track of what data is being collected, why it’s being collected, and where it’s stored.
Addressing the need for data privacy at this point is a huge resource lift that likely requires extensive manual work to map out how data is flowing through the system. But code is still being shipped, so new data is being collected and stored. This makes any data mapping exercise pointless, with results that are always out of date.
User Control Over Data
Users are demanding control over their data. They have the right to be forgotten or to turn off access to specific services. So even if you are able to disentangle the orphaned data, you need a way to connect this data to the user’s identity and provide a means to manage it.
Providing this level of control to an existing system becomes a nightmare to manage. You end up having to create and manage different access policies based on services you provide so that a user can fine-tune which services can see their data.
Additionally, some services may need different levels of access. For example, your customer support agent might need to see the last four digits of a customer’s social security number, while your service for checking credit scores might need the full social security number.
As comprehensive and sophisticated as our infrastructure and technology stacks have become, we lack a good solution to solve this problem. This leaves us with an ad hoc approach that generates an unmanageable mess of technical debt that scales up as your business scales.
Compliance with Regulations
There’s an increasing number of data security and privacy laws, such as the General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA). Other countries like Australia, Japan, Brazil, and South Korea are following suit. Navigating all the rules and regulations is increasingly complex.
If you’ve painstakingly mapped your data and built access policies for users to control how their data is used, your solution needs to be adaptable to changing and additional regulations. Again, our existing stacks are failing us here.
Where Do We Go From Here?
If our existing technology is failing us, then what do we do?
We need to work the problem of data privacy the same way that engineers have worked other problems in the past. Just like we did to address problems in the past like scalability, code bloat, and real-time analytics, we need to do the same for data privacy.
There are two reasons our existing systems are failing us. The first is that the stage in which we try to address privacy happens too far downstream in the product life cycle. The second issue is that our existing stack doesn’t have a solution for data privacy that addresses data governance, residency, compliance, and security.
Data Privacy in the Product Life Cycle
In modern product development, we follow a virtuous cycle where we plan, design, make sure code is well tested, and scale up the implementation. These are all part of a continuous process that defines the product life cycle.
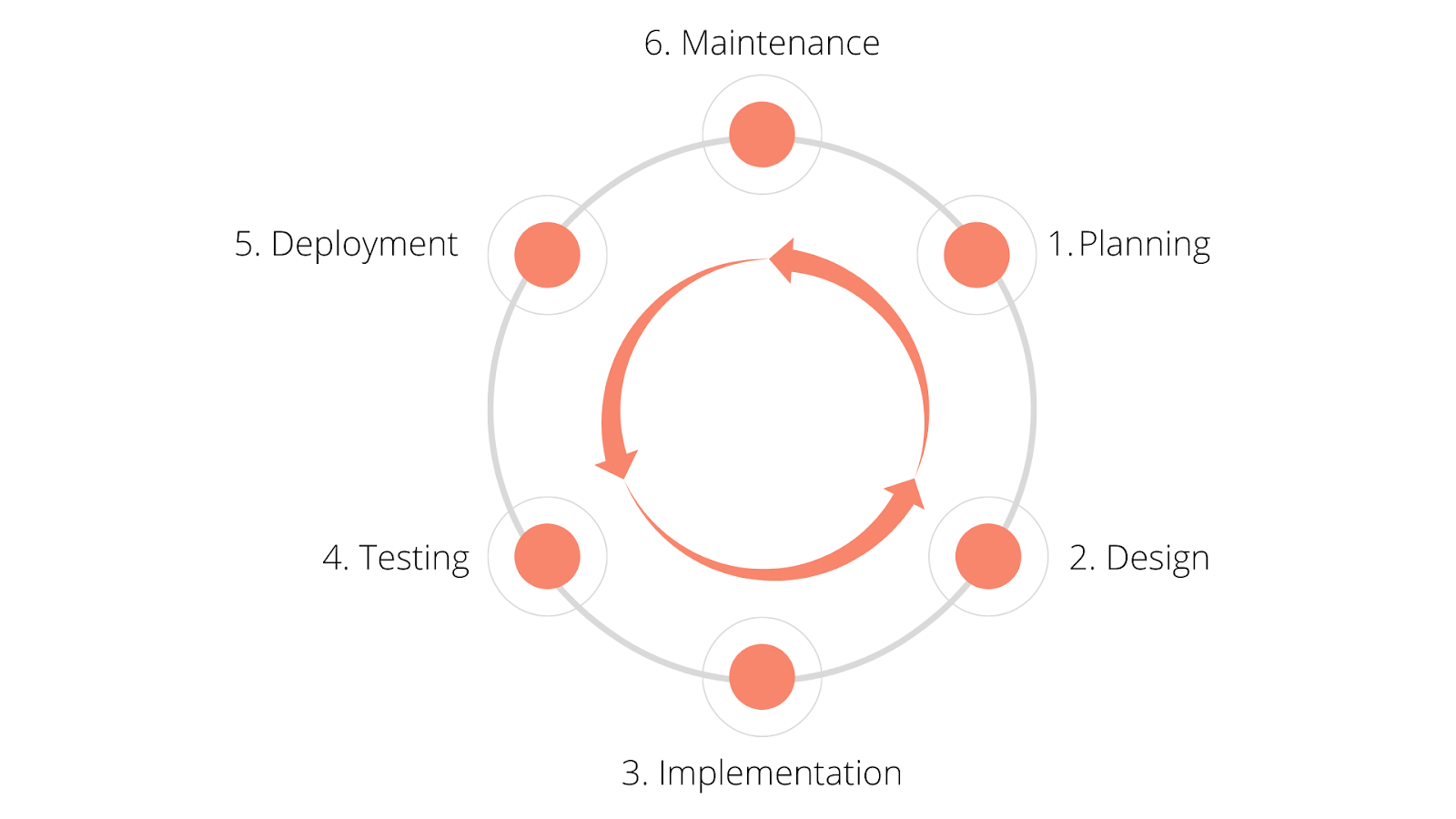
However, data privacy is generally not part of this process. Features are planned, designed, and implemented long before we think about the privacy implications. This results in issues like the orphaned data problem mentioned earlier.
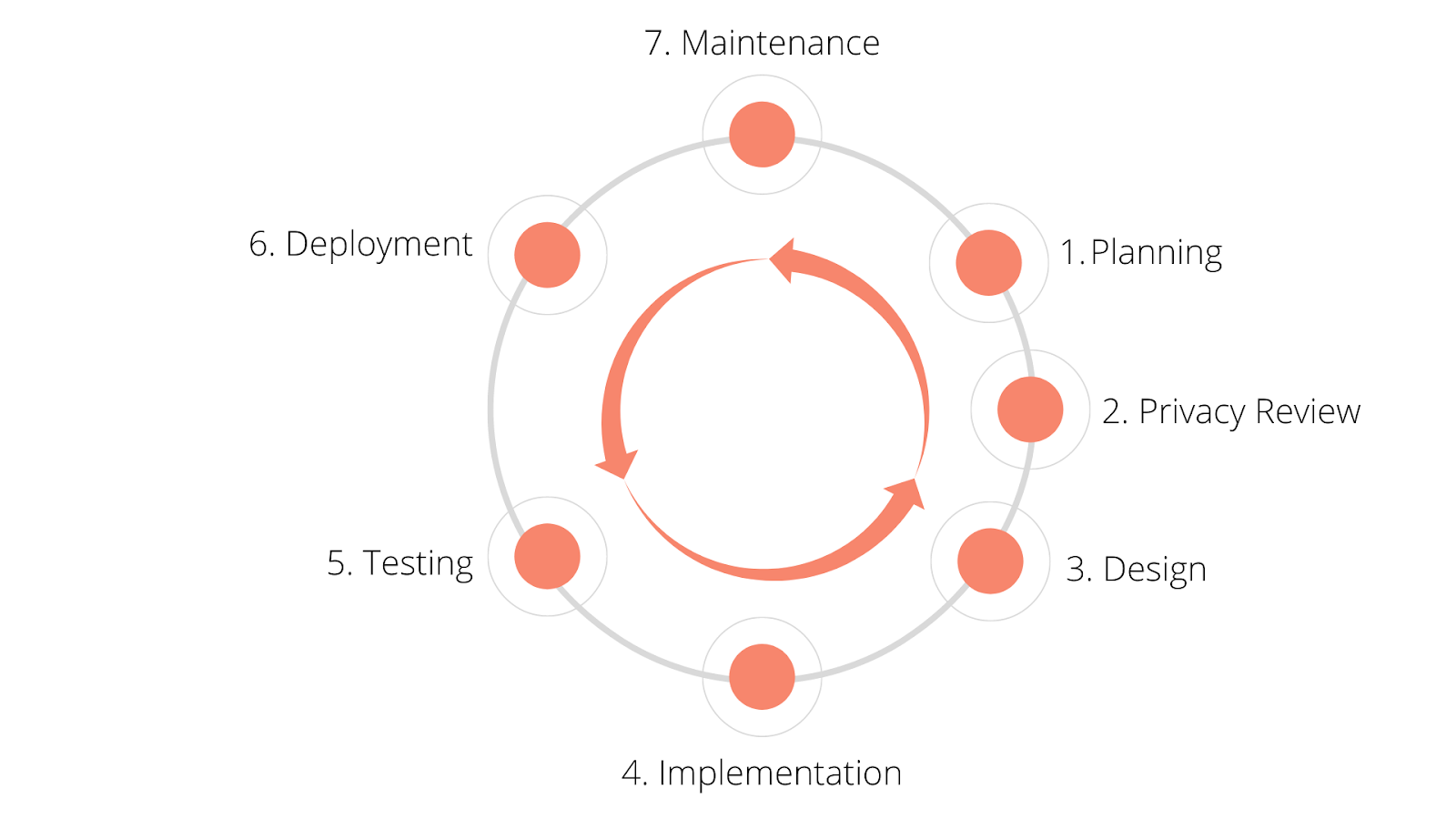
Companies like Apple and Google incorporate privacy during the planning phase of software development. This way, if needed, a solution for data privacy is baked into the feature, not awkwardly bolted-on later.
We need to shift data privacy left in the product development process and make it a continuous cycle. It can’t be an afterthought.
You need to incorporate a privacy process during the planning phase of a feature. This is the time to describe and map the user data that’s important to the feature. The process enforces user control policies and checks to ensure compliance with laws like GDPR and CCPA.
A Technology Solution to Data Privacy
Although it’s not part of the typical engineer’s toolbelt, there is a technology that addresses issues like data governance, residency, compliance, and security and it’s being used by large companies like Apple, Google, and Netflix.
This technology is known as a data privacy vault. A data privacy vault combines security best practices like tokenization and encryption and sophisticated access control to provide limits on how much sensitive data a program or person has access to. The vault architecture isolates and protects sensitive data, while keeping it usable.
Building a data privacy vault is complicated, requiring a range of domain expertise, as described here. But we can’t shy away from complexity when it helps address a fundamental user need. Just as we’ve done so many times as engineers, we must rise to the challenge so we can meet the needs of our users.
Final thoughts
As engineers, we are often inventing the future, creating new powerful applications that people fall in love with. That’s an amazing opportunity, and it’s what drives us to continually innovate and build new products. Just as we take on the responsibility that our inventions will respond quickly to users, be secure, be scalable, and be well tested, we must also take on the responsibility of respecting our users. Respecting our users is about respecting their privacy.
Adhering to regulations and user demands for data privacy doesn’t have to be seen as limiting, but as an opportunity. It just requires a new way of thinking about software development.
Designing for scalability from the outset as well as dealing with known security issues like SQL-injection and XSS attacks are table stakes for the modern developer. Similarly, we need to grow our toolkit again and design for privacy from the start. We also need to follow the best-in-class examples for managing user data and start treating our user data as special, managing it within a zero trust data privacy vault.
Building a data privacy vault from scratch is a huge task and not one every company has the resources to take on. This is why we did it for you. Skyflow Data Privacy Vault APIs offer the same functionality developed by major enterprises without the massive time investment.
To learn more about how Skyflow can help you address the user demand for privacy, please get in touch with us.