
Running Secure Workflows with Sensitive Customer Data
One of the central challenges companies face when it comes to privacy and compliance is balancing the protection of sensitive data with the utility of that data. You can lock the data down and throw away the key, but that’s not very useful. On the other extreme, you can replicate plaintext sensitive data throughout your systems and services, maximizing utility but significantly hurting your security posture and increasing your compliance scope.
So, how can you maximize data security and utility?
In this post, we’ll show how a data privacy vault protects sensitive data without sacrificing the ability to use that data.
Isolate, Protect, and Govern Access to Sensitive Data
In a traditional system infrastructure, sensitive customer PII (Personally Identifiable Information) is collected and then pushed to downstream services, where it ends up being copied, replicated, and fragmented across various apps and services – a problem known as sensitive data sprawl. This means that PII is found throughout various logs, data stores, and dashboards, as shown below.
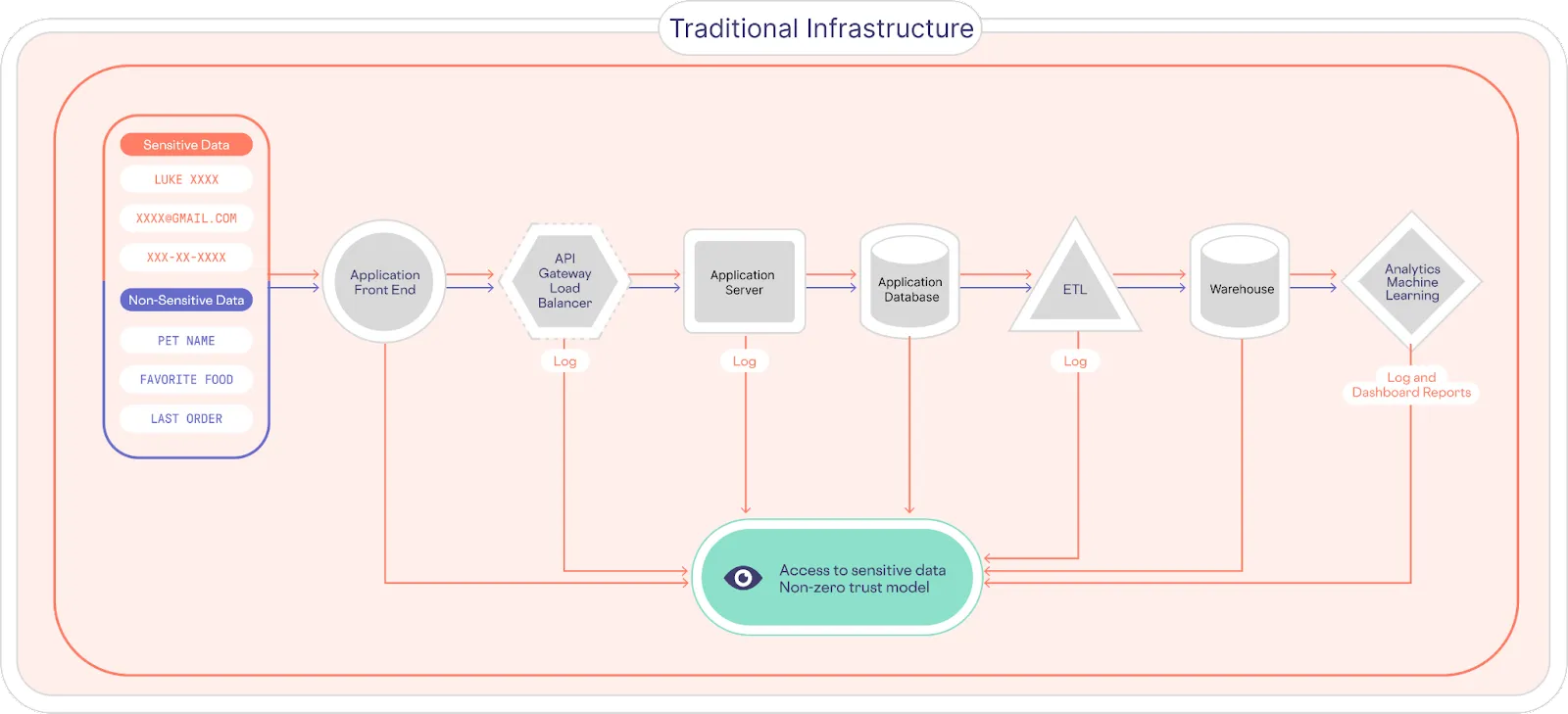
This makes it very difficult for companies to answer basic questions, like “what customer data are we storing?” and “where is it stored?”
This is at the heart of one of the fundamental problems that Facebook is facing. They don’t know where all the user data goes, or what they are doing with it, which makes protecting this data and managing compliance requirements very difficult.
To better understand this problem, imagine that instead of having a single copy of your passport that you keep in a safe place, you instead made thousands of copies and stored them in thousands of locations, and then attempted to protect all of those locations. It sounds ridiculous, but that’s what many businesses traditionally do with customer PII data.
Learn how to isolate and secure sensitive data with a vault. Get your guide →
The Data Privacy Vault
In contrast, a data privacy vault isolates, secures, and tightly controls access to manage, monitor, and use sensitive data. As shown in the image below, customer PII is sent directly to the data privacy vault, where it’s isolated and protected, providing a single source of truth for sensitive data. The rest of the traditional system is effectively de-scoped from the responsibilities of data privacy, data security, and compliance.
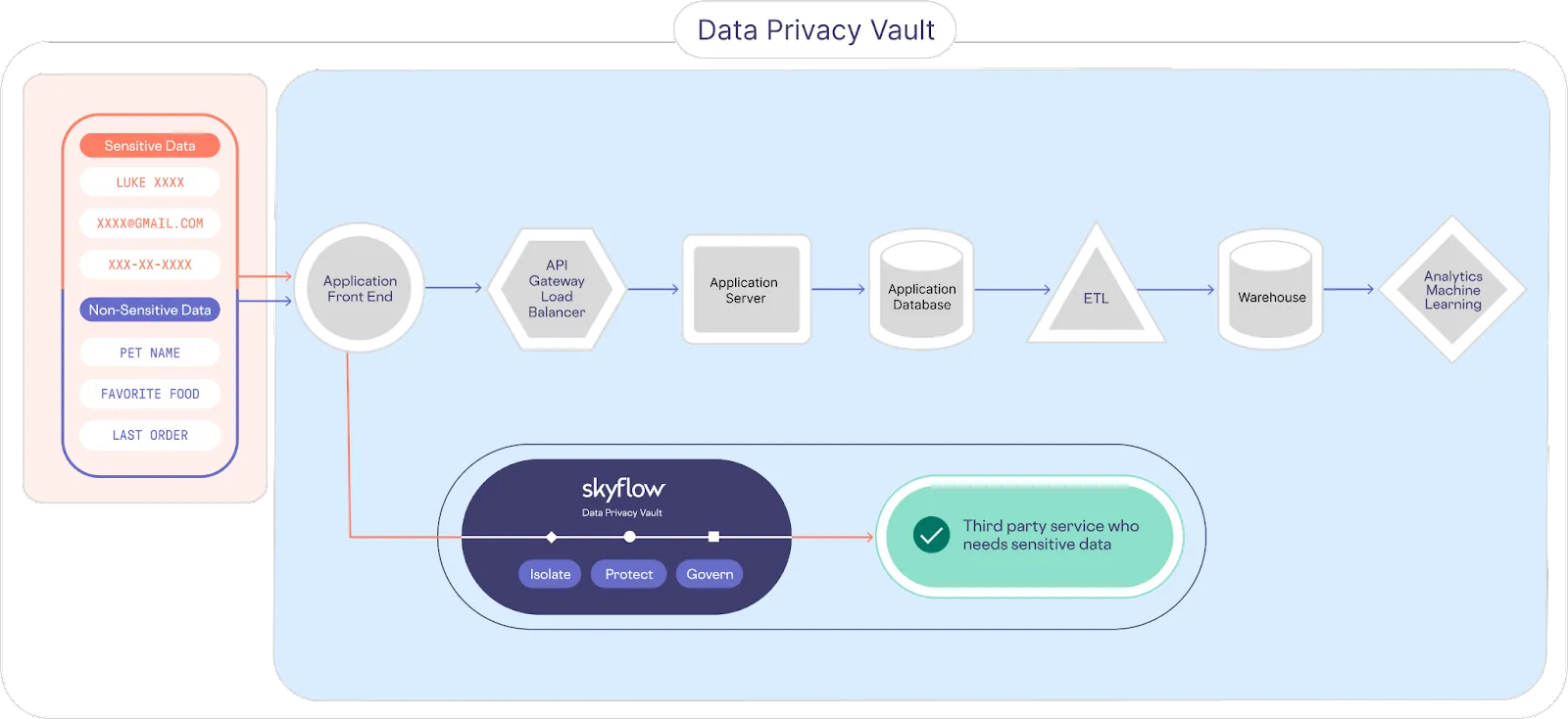
Ideally, sensitive customer data is detected and de-identified as early in the lifecycle as possible and re-identified as late as possible, just prior to usage. In the example architecture shown above, sensitive data is stored within the vault. Non-sensitive tokens are sent back to the application front end and passed to the downstream services.
Access to re-identify sensitive data is controlled via a zero trust data governance model. A combination of service accounts, roles, and policies control access. A policy states which columns a role has access to, how that information is viewed, and even which records (i.e., rows) that role has access to. This gives you fine-grained control over how sensitive data is consumed.
Isolating and protecting sensitive data is critically important to minimizing your privacy and security risks and reducing your compliance burden. But given how many workflows potentially need sensitive data, you also need support for executing sensitive data workflows, including transformations, securely executing code, de-identifying data, and secure data sharing.
In the next section, we’ll discuss new extensions to Skyflow Data Privacy Vault that provide even more extensive support for sensitive workflows that involve PII.
Data Utilization via Support for Sensitive Workflows
Support for executing sensitive workflows over sensitive customer data lets you perform essential operations with this data while keeping it isolated and protected from your existing applications and systems.
These new capabilities let you have your cake (data privacy) and eat it too (data utility).
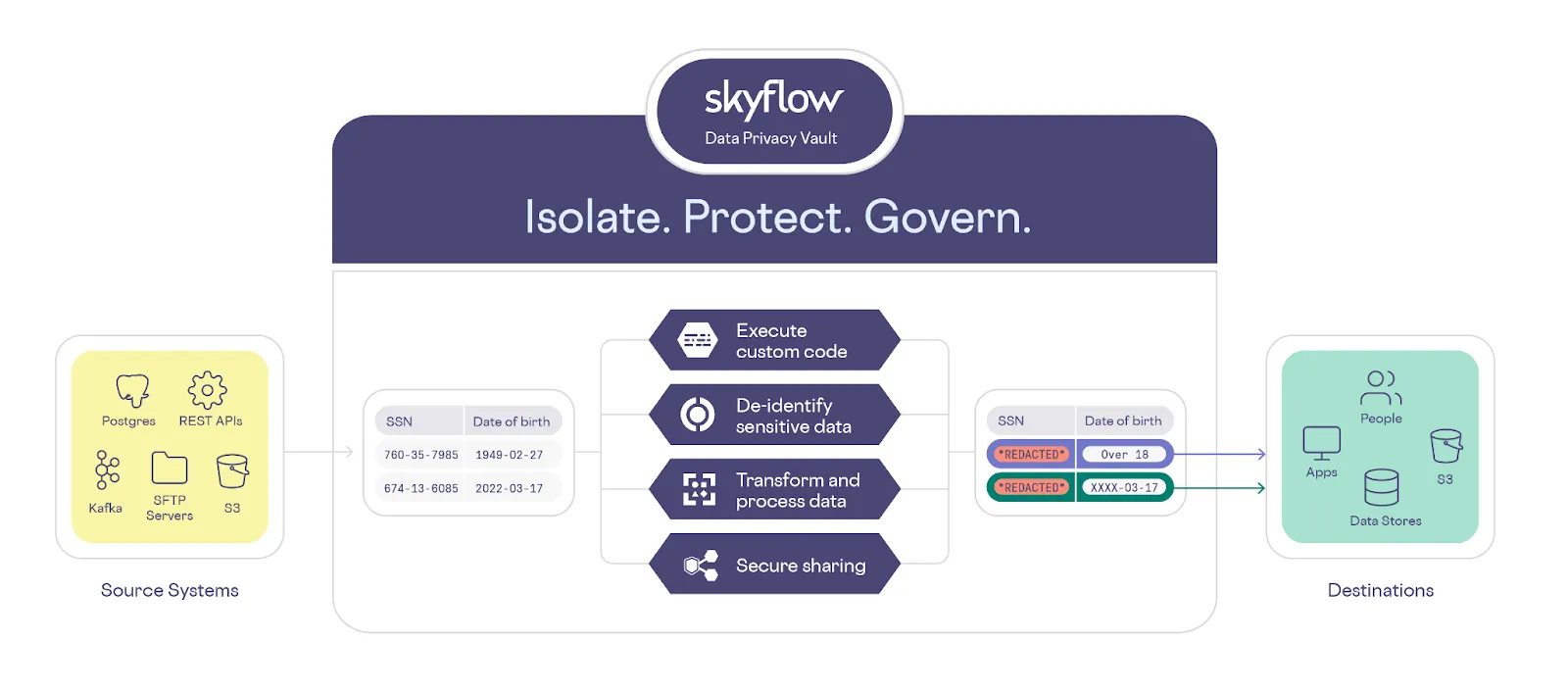
With support for sensitive workflows, a business can execute custom code, de-identify sensitive data, securely share sensitive data, and transform and process data in a secure environment that meets or exceeds compliance requirements like PCI DSS, GDPR, CPRA, and HIPAA.
Skyflow Data Privacy Vault supports sensitive workflows using a combination of features – Connections, Functions, and Pipelines. Each of these are described below.
Learn how to isolate and secure sensitive data with a vault. Get your guide →
Connections
Skyflow Connections is a tokenization and connectivity service that lets you securely share data between your Skyflow Vault and trusted third-party services. Skyflow Connections provides a stateless HTTPS proxy that can handle sensitive data integrations across frontend applications, backend services, and trusted third parties – letting you collect and use sensitive data without needing to process, store, or protect it yourself.
Without a service like Connections, you're stuck handling sensitive data directly, which expands your compliance scope.
Instead, you can use Connections to both protect the privacy of sensitive data and use it for business critical workflows. In this architecture, sensitive data is sent directly from the frontend application to the vault. Tokenized or de-identified data is sent back to the frontend application and stored in the backend services. Later, the backend can call a specified third party API by including tokenized data when calling a connection (an integration with a third party API). The tokenized data is detokenized securely within the vault, which calls the third party API using sensitive data. The resulting architecture looks like the following:
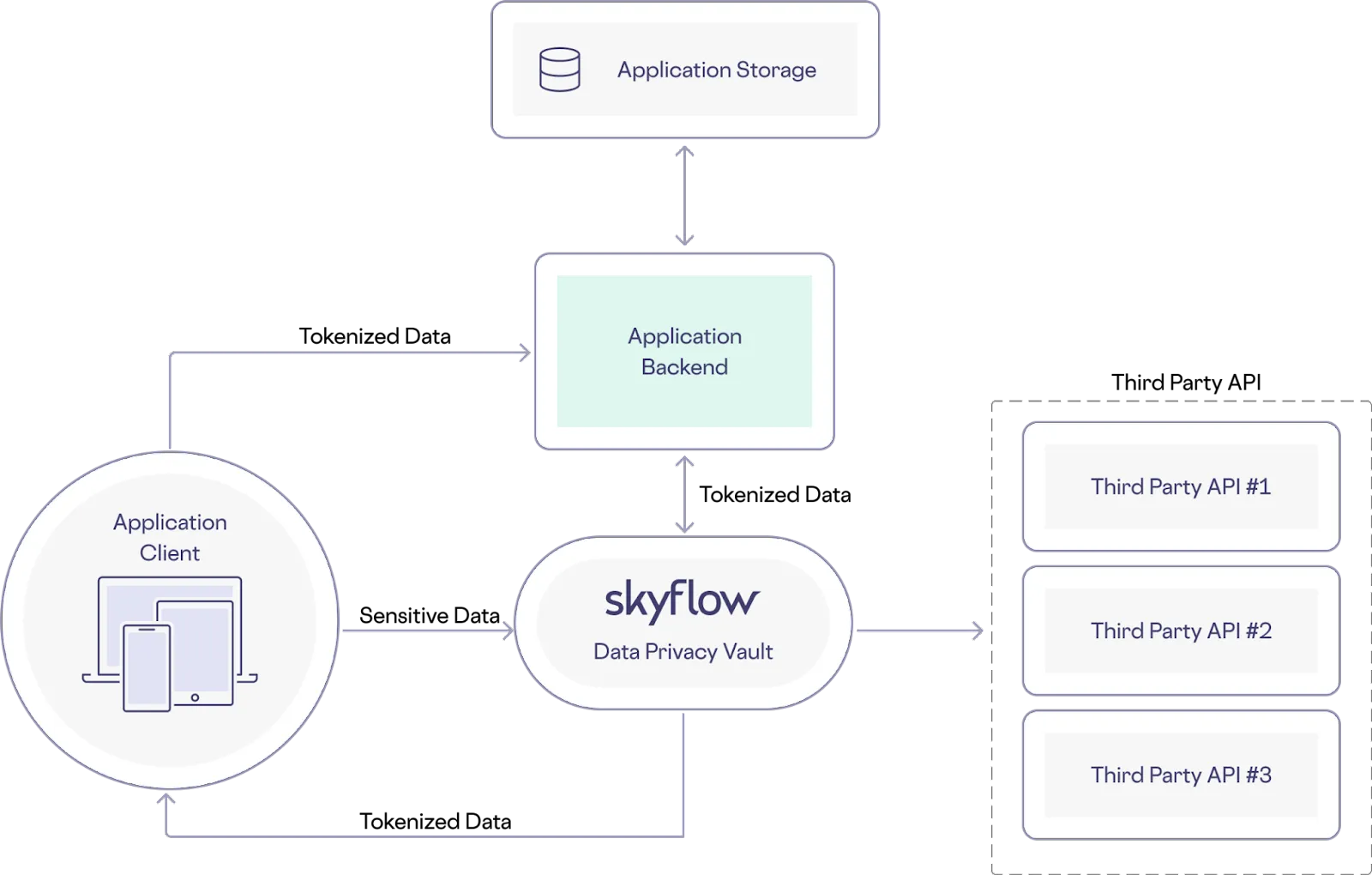
Skyflow supports many connections to trusted third-party services out of the box, including connections to Stripe, Moov, Adyen, and PostGrid – but you can also build your own connection via the Skyflow Connections API or using a web-based UI provided in Skyflow Studio.
Functions
Skyflow Connections works as a prescriptive gateway solution to descope your environment from sensitive data. It does so by mapping incoming requests from your environment to specific actions and fields within the context of a Skyflow Vault schema.
While this addresses many use cases, there are situations where you might need to modify or transform the inbound data (data sent to Skyflow) or outbound data (data sent by Skyflow).
Skyflow Functions lets you write and execute code within the secure vault environment so you can modify or transform either inbound or outbound data when using Skyflow Connections to integrate with third party services.
Functions lets you manipulate both inbound and outbound data, so you can support use cases like extracting sensitive data from an image and storing the extracted data within the vault, or extracting a file from the vault that can be relayed to a third party service.
Your custom logic is confined to the Skyflow Vault environment, subject to fine-grained data governance and zero trust access controls that you configure. This means you can perform operations on your customers’ sensitive data without your services or infra interacting directly with that data.
For example, in the following image, when the Connections API is called with tokenized data, custom code is executed that transforms, saves, or otherwise manipulates inbound data before it is relayed to trusted third party APIs:
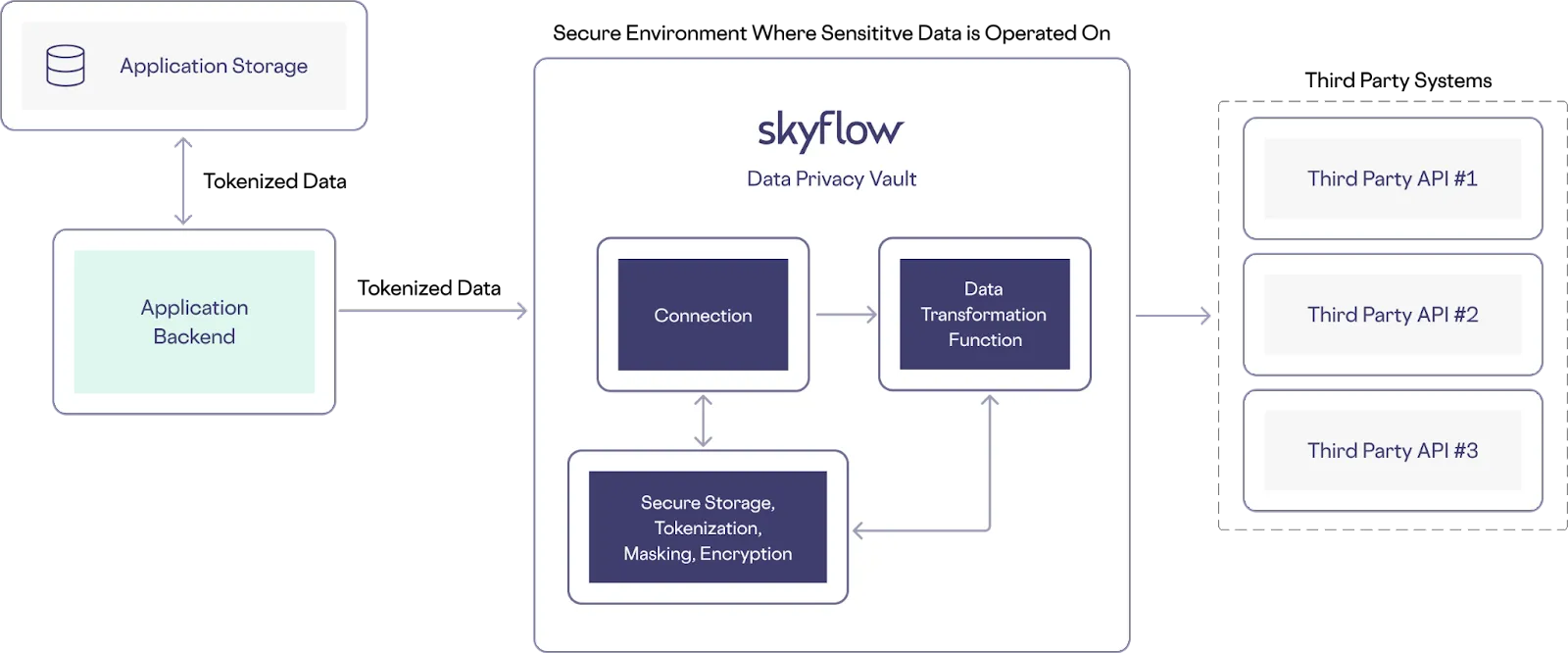
This approach gives you even more control and flexibility when handling the sensitive data that you need to use for integrations with trusted third party services.
Pipelines
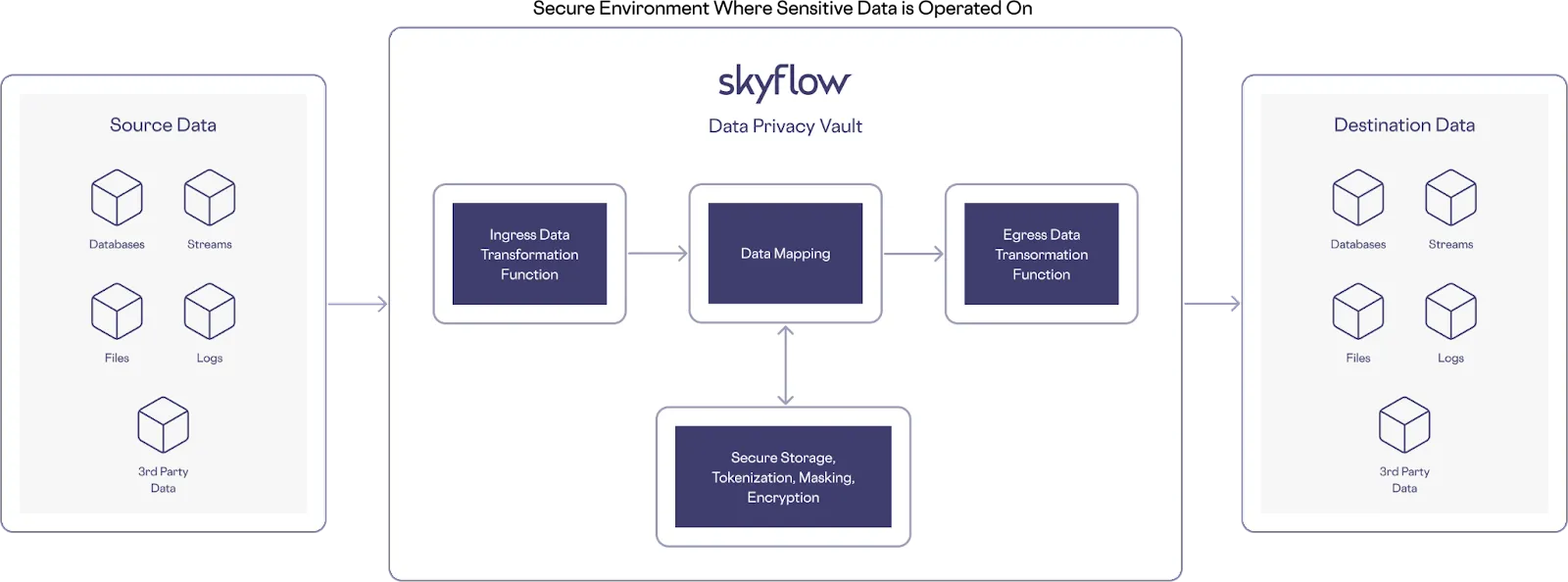
Skyflow Pipelines is a Skyflow-hosted prescriptive ETL data pipeline that detects and tokenizes sensitive data in large files, while storing plaintext sensitive data elements in the vault. You can then use these Skyflow-provided tokens as stand-ins for sensitive data elements within your downstream services, such as data warehouses or data lakes. While Skyflow Connections helps you protect data privacy in HTTP based transactional workflows, Skyflow Pipelines is specifically designed to support file based transfer protocols.
Without Pipelines, you would need to expose your data analytics pipeline to sensitive data, which would bring any compliance requirements that you’re subject to (PCI, HIPAA, GDPR, etc.) to bear on your data analytics pipeline and downstream analytics systems. Not only does this compliance burden increase your time to market, it also increases the potential for theft or misuse of sensitive customer data because anyone with access to your data warehouse has access to that data.
Instead, you can use Skyflow Pipelines to avoid increasing your compliance or security scope when processing files that contain sensitive data. Sensitive data processing happens securely within your vault environment and is compliant with regulatory requirements.
Here’s an example architecture that uses Skyflow Pipelines:
Examples of Sensitive Workflows with a Data Privacy Vault
Here are a few examples of use cases for running sensitive workflows with a Skyflow Data Privacy Vault:
- Securely Passing Data to Third Party Services
- Providing a Consistent API Across Disparate Services
- Data Transformation
- Passing Sensitive Files to Third Party Services
- Detection and Redaction of Inbound Data
Securely Passing Data to Third Party Services
When using payment processing services like Stripe, Adyen, Braintree, and so on, a business often reaches a stage where it makes sense to use more than one payment processing vendor.
Using Multiple payment processors gives your business flexibility, more control over fees, and lets you expand internationally because you’re not limited by the geographic footprint of a single payments vendor.
Connections gives you a very high level of flexibility around payment processing.
You can store your customers' PCI data in your vault and use the Connections API to proxy calls to any third party payments vendor. With a Skyflow Vault, you can offload PCI compliance and with Connections, you can use the sensitive data stored in the vault to integrate with third party services (as shown below).
Here’s how this works in the example architecture shown below:
- PCI data that is securely collected from the frontend application is sent to the vault through a different connection endpoint based on the third party service being used
- PCI data is forwarded to the third party payment provider
- Skyflow tokens are returned to the frontend application
- Tokens are stored in the application backend database
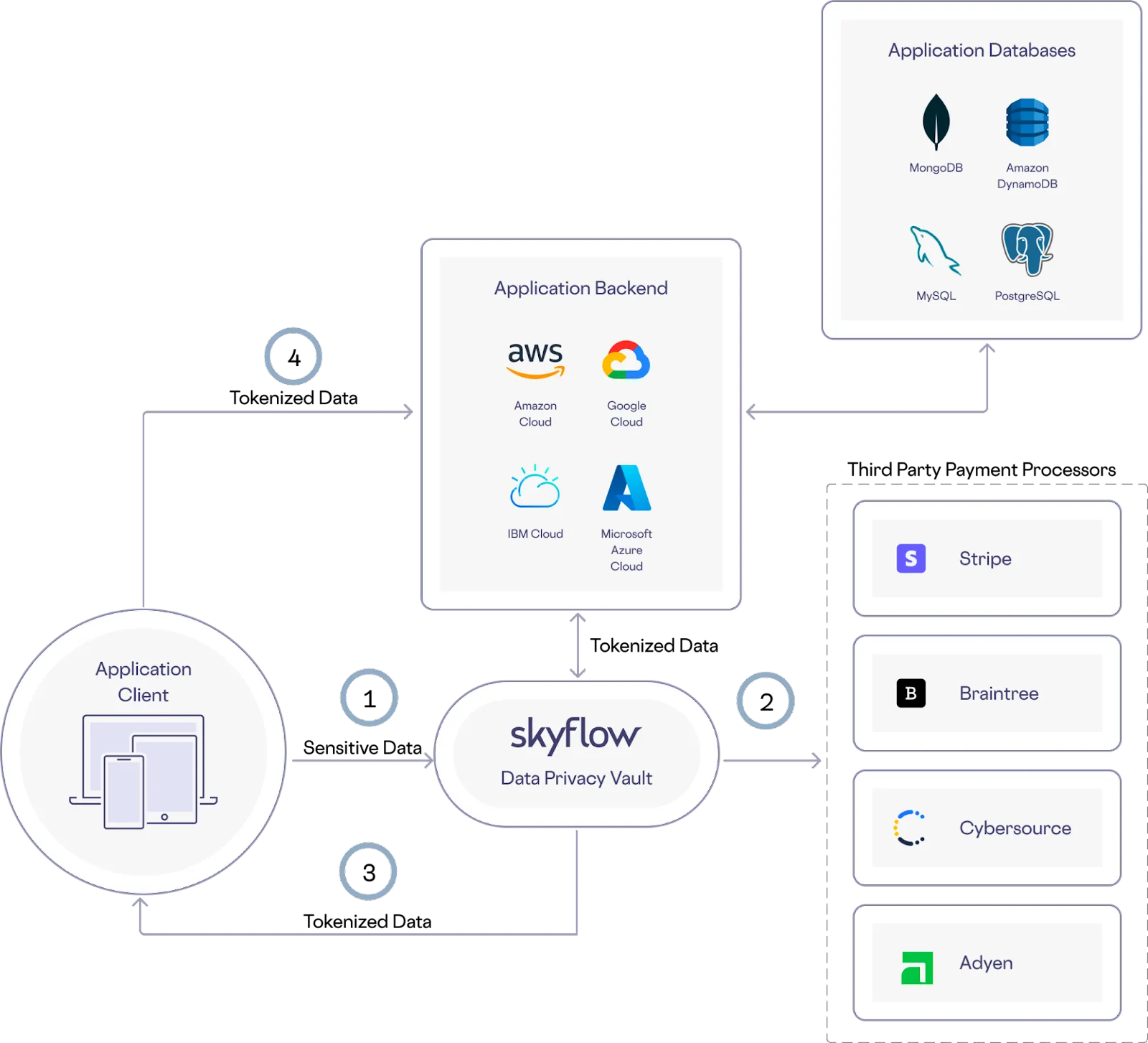
With this architecture, your backend can later use PCI data tokens to process transactions using stored cards without exposing any of your backend services to sensitive PCI data.
Providing a Consistent API Across Disparate Services
Building on the example shown above, if you’re supporting multiple payment processors, each processor has a unique API. Typically, your Connections API call is going to look similar in format to the third party service’s API. Thus, if you were using three different payment processors, you’ll have three connections, and the body and authentication method for each will be unique.
By executing custom code with a function within your data privacy vault, you can keep the API semantics consistent for all three connections by transforming the received payload into the format that each third party needs. This hides the complexity of the transformation with a function that is executed automatically on ingress (when the API call reaches Skyflow).
Data Transformation
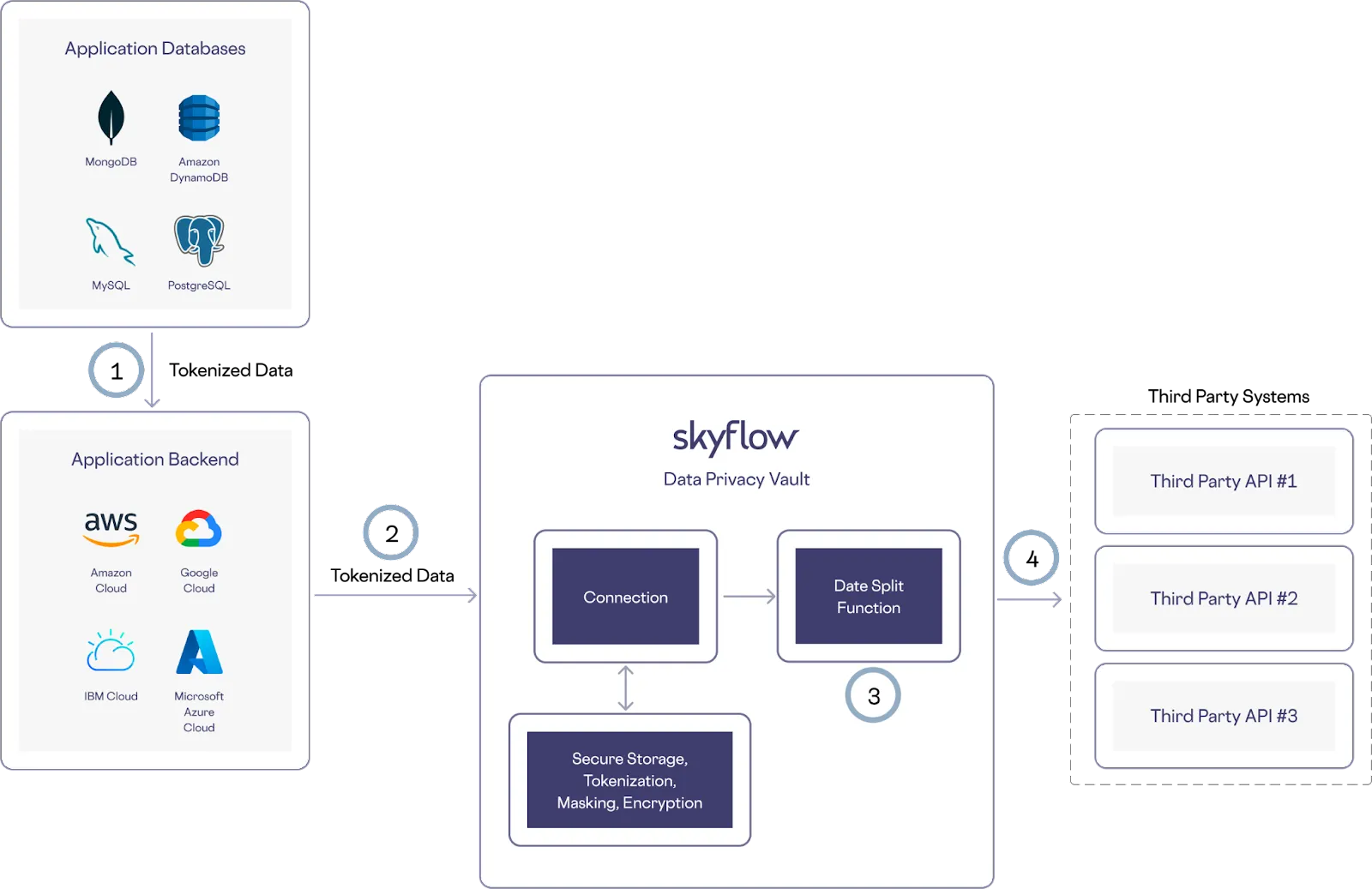
The way you choose to store your data might not always perfectly match up to a third party service. For example, you might store your dates as a datetime field, while a third party expects the date to be split across several fields for day, month, year, and time. Executing custom code lets you transform the data as needed securely within the vault.
Here’s how this works in the example architecture shown below:
- Tokenized data is retrieved from the application database
- Backend systems make an API call to a connection
- A custom function splits the datetime field into time, day, month, and year components securely within the vault
- Skyflow passes the reformatted date and time data on to the trusted third party service
Passing Sensitive Files to Third Party Services
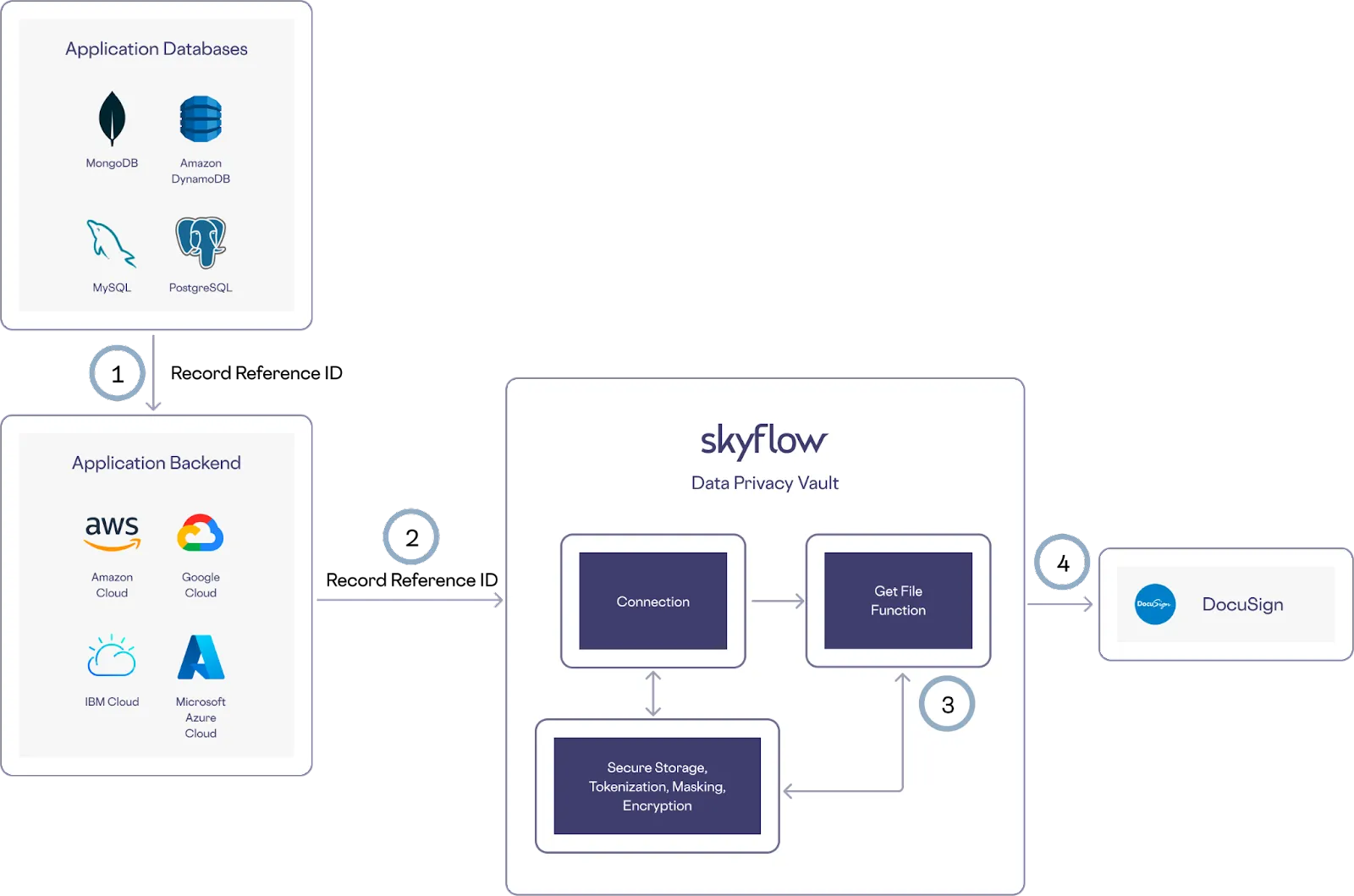
You might store sensitive files within your vault that you need to pass to a trusted third party service. For example, you could store a file for a contract that you need to send to DocuSign for signatures. You can perform this operation without touching any sensitive data using a custom function created with Skyflow Functions that runs securely within your vault.
Here’s how this works in the example architecture shown below, starting after you create a custom function and store the contract in your Skyflow Vault using Skyflow’s frontend SDK:
- To call DocuSign, retrieve the reference record ID from your application database
- Use that reference record ID to call a connection while referencing the record stored in your Skyflow Vault
- The custom function you created takes the record reference and extracts the file from the vault
- The vault forwards the contract file on to DocuSign
Detection and Redaction of Inbound Data
Skyflow Pipelines supports many scenarios where you need to detect and redact sensitive data to protect the privacy and security of that data.
For example, if you integrate with a card network like Visa, they’ll generally send you daily reports on credit card transactions via sFTP. These reports contain PCI data elements such as credit card numbers (PANs), and these PANs need to be detected and redacted (replaced with tokens) before your systems read any of this data. This prevents your systems from falling under the scope of PCI compliance.
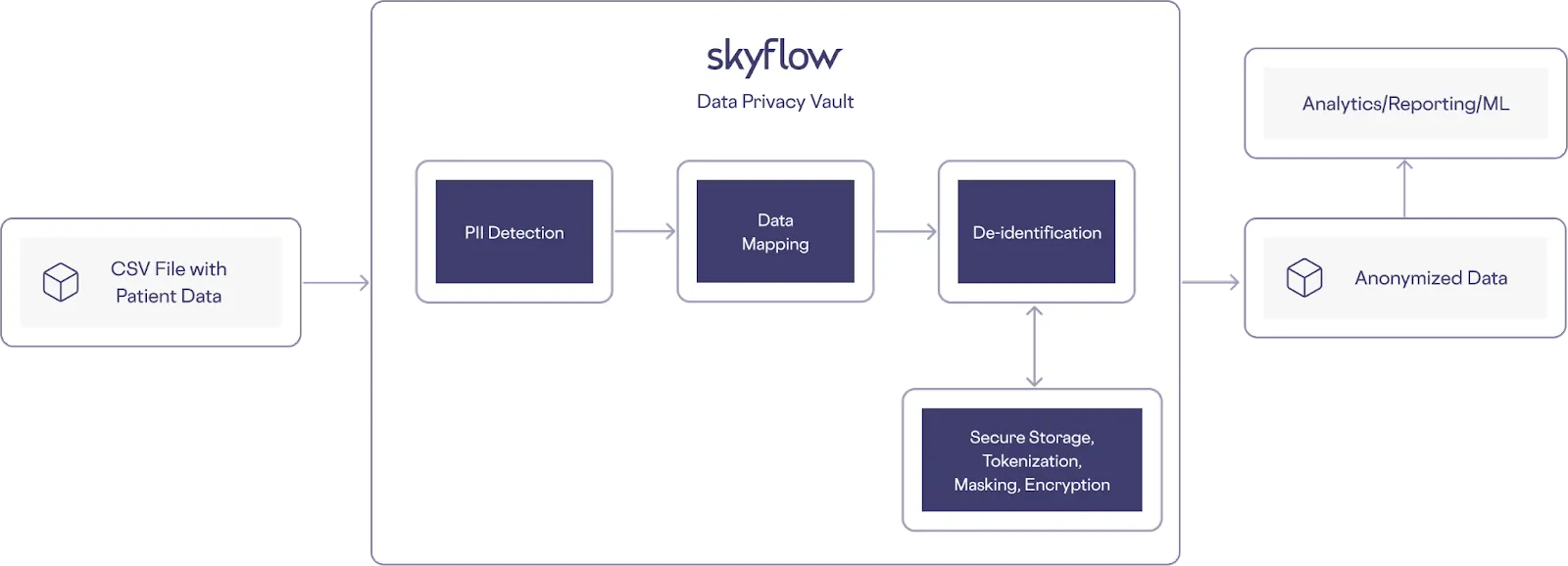
Another scenario where detection and redaction are useful is when handling data about clinical trial participants. Participants’ sensitive data (names, addresses, etc.) could be stored in CSV files along with clinical trial results. To protect the privacy of this sensitive data, you should detect and tokenize it as shown in the following example architecture, before it’s compiled into a database for analysis:
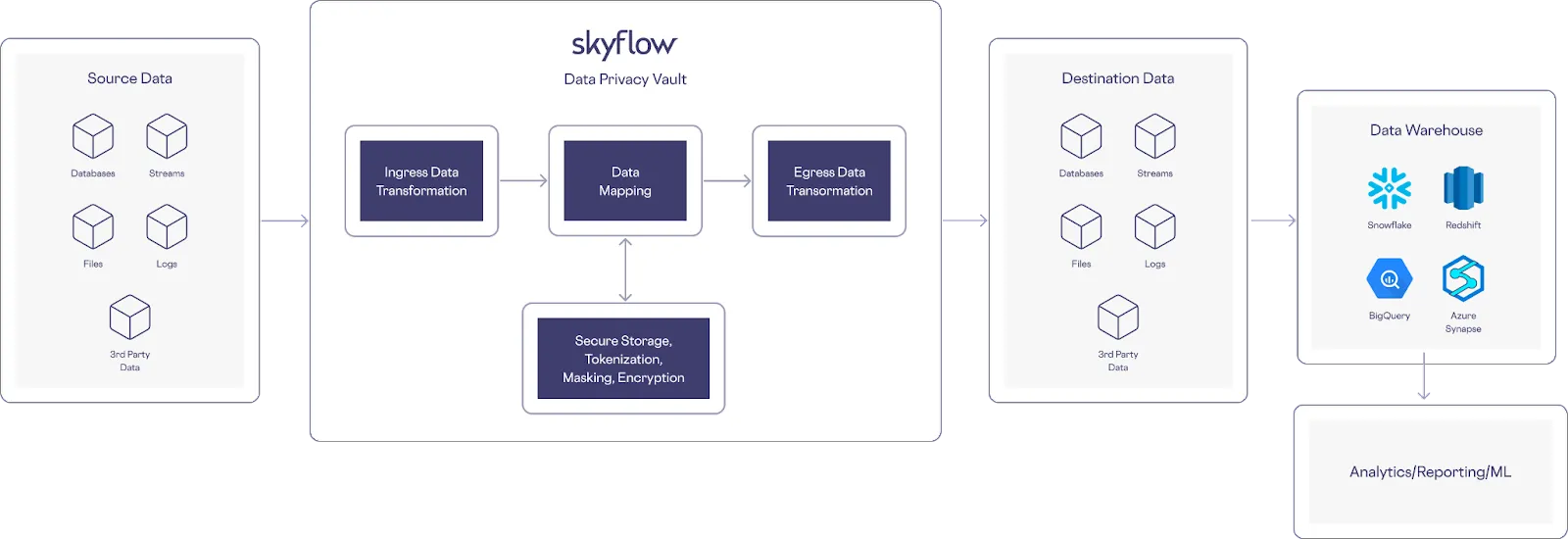
Another scenario to consider is when you need to detect and tokenize sensitive data as it lands in an S3 bucket, so that bucket’s payload is “clean” before it’s pushed into a data warehouse. You can support this scenario with an architecture like the following:
What’s Next?
Customer data is core to how every business builds and maintains customer relationships. And customer trust is at the core of these valuable relationships. To build and maintain trust, it’s important to make sure that customer data is secure and consistently handled in a privacy-preserving manner.
A critical piece of the customer data journey is the ability to safely operate on sensitive data to support critical workflows. This can include processing, transformation, running computations, and running custom logic on this data. This also includes securely sharing this sensitive data with trusted third parties. And you need to do all of this without compromising on data privacy or security, or expanding your compliance scope.
But as any developer knows, securely utilizing sensitive data within a codebase is complex. And the stakes are high, because any mishandling of sensitive data results in fines and data breach reports that can damage customer trust. This is why regulations constrain who can use sensitive data, as well as when and how it’s used. These restrictions make it hard to utilize and operate on this data within your codebase the same way you would with other types of data.
With support for executing sensitive and secure workflows in your data privacy vault, you have the power to utilize, operate, and run customer data workflows and transformations without worrying about compliance and data security.