Private LLMs: Data Protection Potential and Limitations
Private LLMs are trending as a solution for AI privacy concerns, yet they may not fully safeguard our data as hoped. Discover their data protection promise and the limits in this article.
The explosive rise of GPT and other Large Language Models (LLMs) in the field of Generative AI has captured the attention of companies worldwide. Preliminary research shows significant productivity gains for users of generative AI, reminiscent of past technological revolutions. Only six months after general release, as many as 28% of occupations already require some use of ChatGPT.
As the utilization of AI continues to grow, many are raising concerns around privacy and compliance. Recent events have brought these concerns to the forefront of business leaders’ minds, highlighted by Samsung's ban on ChatGPT due to leaks of its sensitive internal data, Italy's initial national prohibition (subsequently lifted) on access to ChatGPT, along with Canada's investigation into ChatGPT and OpenAI following a complaint about unauthorized collection and disclosure of personal information.
While enterprises scramble to evaluate and build on LLMs, potentially leveraging their own customer or internal data to build domain-specific applications, addressing the privacy concerns must be accounted for as enterprises shape their AI strategies.
An emerging trend and recommendation for tackling the privacy challenge for LLMs is to build on private LLM offerings available from major cloud providers or architecture and run a self-hosted LLM. In this article, we take a deep dive into what private LLM is, why you might use it, and most importantly, the limitations.
Learn how to protect sensitive data in AI applications. Download whitepaper →
Understanding the Privacy Challenges for LLMs
Whether you're utilizing tools like ChatGPT or developing your own generative AI system, privacy poses a significant challenge. Products such as OpenAIs GPTs cannot guarantee data privacy, as demonstrated by the recent “poem” prompt injection attack uncovered by Google DeepMind researchers. Additionally, Google’s Gemini’s Privacy Hub states “Please don’t enter confidential information in your conversations or any data you wouldn’t want a reviewer to see or Google to use to improve our products, services, and machine-learning technologies”.
Unlike conventional applications, LLMs have an indelible memory and lack a straightforward mechanism to “unlearn” specific information. There is no practical "delete" button for sensitive data stored within a LLM. In a world where a “right to be forgotten” is central to many privacy tenets, LLM presents some difficult challenges.
Despite the challenges, companies are looking to invest in building domain specific LLMs trained on their own data. For example, Retrieval Augmented Generation (RAG) is becoming the emerging pattern that is used with fast changing data. The source data for RAG may contain customer, employee, or proprietary information.
Sensitive data, like internal company project names, dates of birth, social security numbers, or healthcare information, which can find its way into LLMs through various channels:
- Training Data: LLMs are trained on vast datasets that may contain personally identifiable information (PII). If proper anonymization or redaction measures are not applied, sensitive data enters the model during training and could potentially be exposed later.
- Inference from Prompt Data: LLMs generate text based on user input or prompts. Similar to training data, if the prompt includes sensitive data, it flows into the model and can influence the model’s generated content, potentially exposing this data.
- Inference from User-Provided Files: Beyond simple text prompts, LLM systems allow users to provide documents or other files that might contain sensitive data. These files are processed by LLM-based AI systems such as chatbots, translation tools, or content generators. Similar to prompt data, the sensitive information within the files flows into the model and can potentially be exposed during content generation. This is the common approach used for RAG models.
To help address potential PII leaks to generally available LLMs, enterprises have been encouraged to move to private LLM.
Private LLMs as a Potential Solution for LLM Privacy
Private LLM is a LLM hosted within your own compute environment. This could be a self deployed open source model or an LLM available via VPC from one of the major cloud providers.
There’s several reasons why an organization may choose private LLM over using one of the publicly available LLM services like OpenAI, Cohere, or Anthropic.
- You want full control and customization over the model
- You need more-up-date data in the LLM than currently available in a public model
- You need customer-specific data in your LLM and you’re concerned about sharing the data with a public provider
To see the difference between public and private LLM, let’s consider building a RAG model under both approaches. RAG is one of the most common approaches to improving performance for a LLM for specific tasks and domains. The idea is to pair information retrieval with a set of carefully designed system prompts to anchor LLMs on precise, up-to-date, and pertinent information retrieved from an external knowledge store. Prompting LLMs with this contextual knowledge makes it possible to create domain-specific applications that require a deep and evolving understanding of facts, despite LLM training data remaining static.
In the image below, the front end and orchestration layers are hosted within your cloud environment, while the vector database and the LLM are both remote and managed by third-party services like Pinecone and OpenAI.
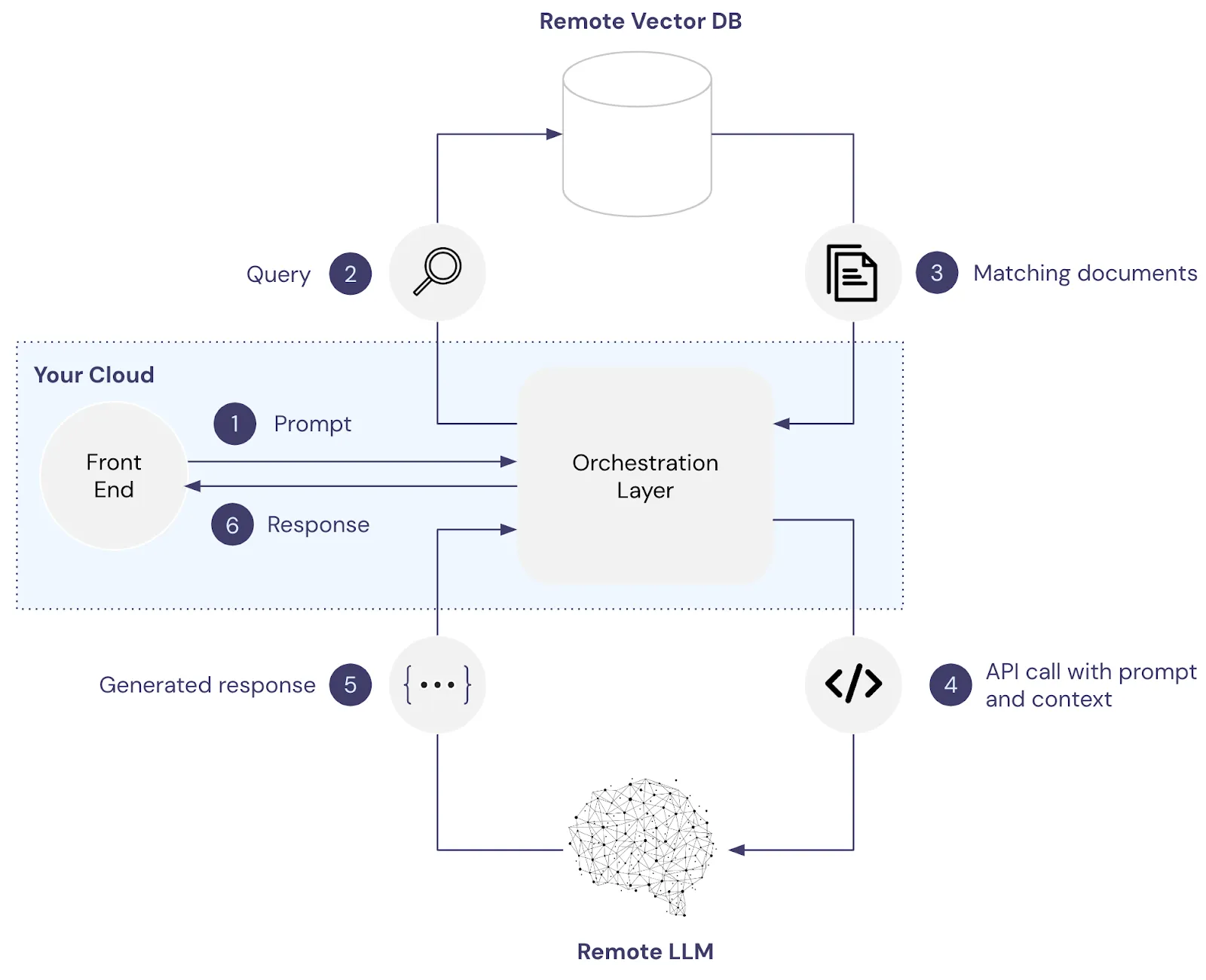
We can modify this architecture by moving both the vector database and LLM internal to our environment as shown below. With this setup, no information shared with the model or vector database is transferred across the Internet.
Note: Although the graphic shows this approach with a self-hosted model, a similar approach is supported by all major cloud providers like Google, Microsoft, AWS, and Snowflake where you connect to a model via VPC, keeping any data shared from flowing across the network.
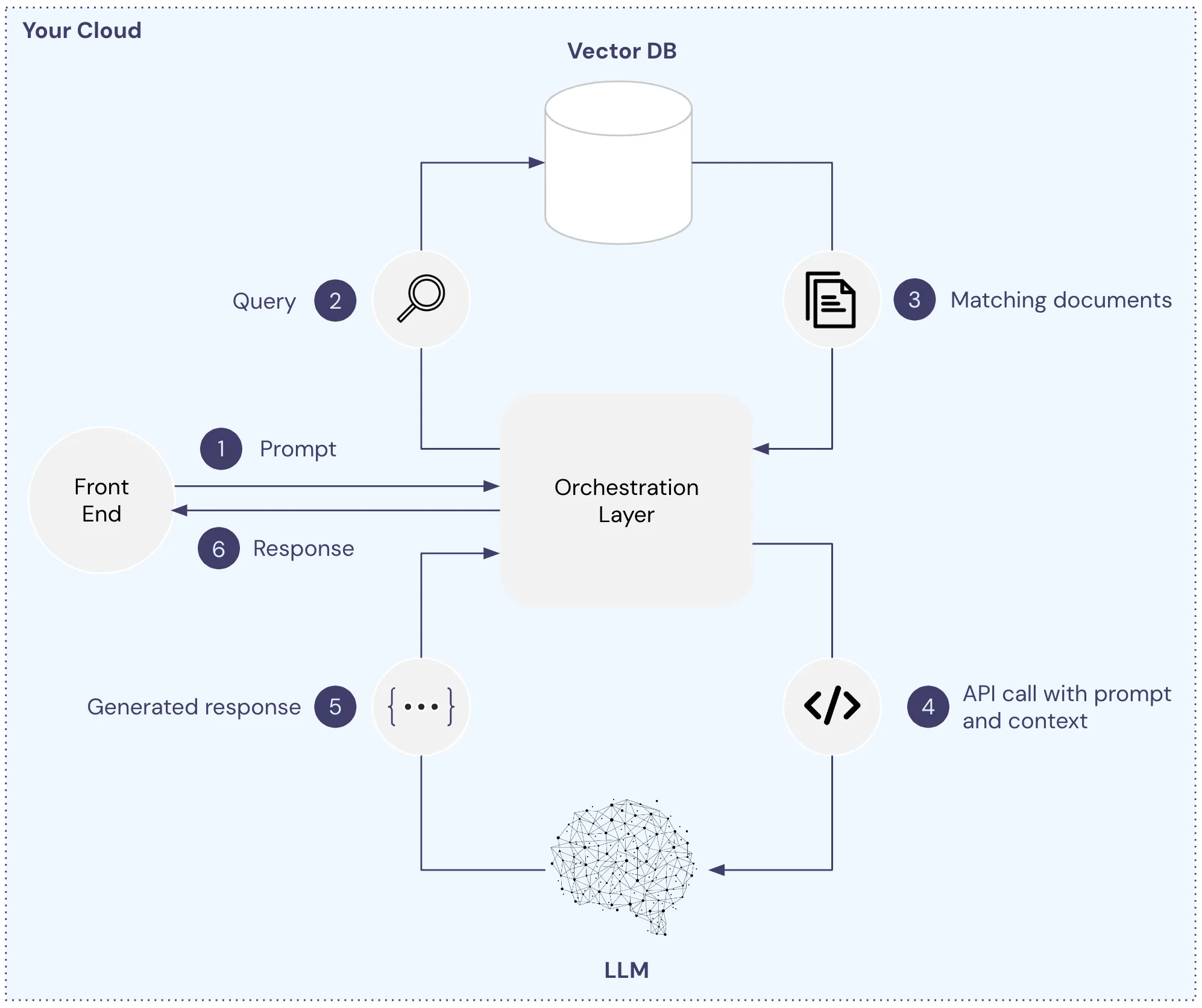
From a privacy point of view, private LLM seems attractive as any sensitive data will only be available within a controlled environment. It doesn’t need to be shared across the Internet with a public LLM service. You can limit access to the LLM to authorized users, there’s no data transfer to third-party services, helping reduce the potential attack surface. However, despite these advantages, there are still many limitations as a solution for security and privacy with LLMs:
- No fine-grained access control
- Lack of enterprise governance
- Difficult to comply with privacy regulations
- Increased maintenance and compute costs
- Difficult to run multiple models
We discuss each of these limitations in detail in the next section.
The Privacy Limitations of Private LLM
Whether you’re running an open source LLM on your own servers, deploying a model within Snowflake’s containerization service, using Google’s Vertex AI, or Microsoft’s Azure OpenAI Service, private LLM gives you model isolation, not actual data privacy.
Putting a protective barrier around your LLM but trusting everyone that interacts with it is a bit like the legacy security approach of creating a security perimeter around your infrastructure and then assuming anyone within the perimeter is to be trusted. In modern security this approach should only be considered an initial layer of defense, not your full answer, and this is just as true for LLMs.
In the following, we cover the limitations of private LLM as an approach to data privacy. These are challenges that are essential to overcome as you move beyond proof of concept and demoware to live production systems.
No Fine-Grained Access Control
Unlike a traditional software application where we can control data access by restricting what rows and columns a user has access to, with a LLM, there’s no rows and columns to manage. This means, regardless of whether you’re using private or public LLM, traditional methods for data governance breakdown in a generative AI world.
The fundamental question we need to be able to answer is, how do you guarantee a response from the model only contains information that the given user has the rights to see?
For example, imagine that customer service agent “Bob” is talking to the LLM on behalf of “Cindy” the customer. Then Bob shouldn’t accidentally see data about Dave, Dave shouldn’t be able to access Cindy’s information, Bob shouldn’t have access to all of Cindy’s personal information, but Cindy interacting with the same LLM should have access to her information.
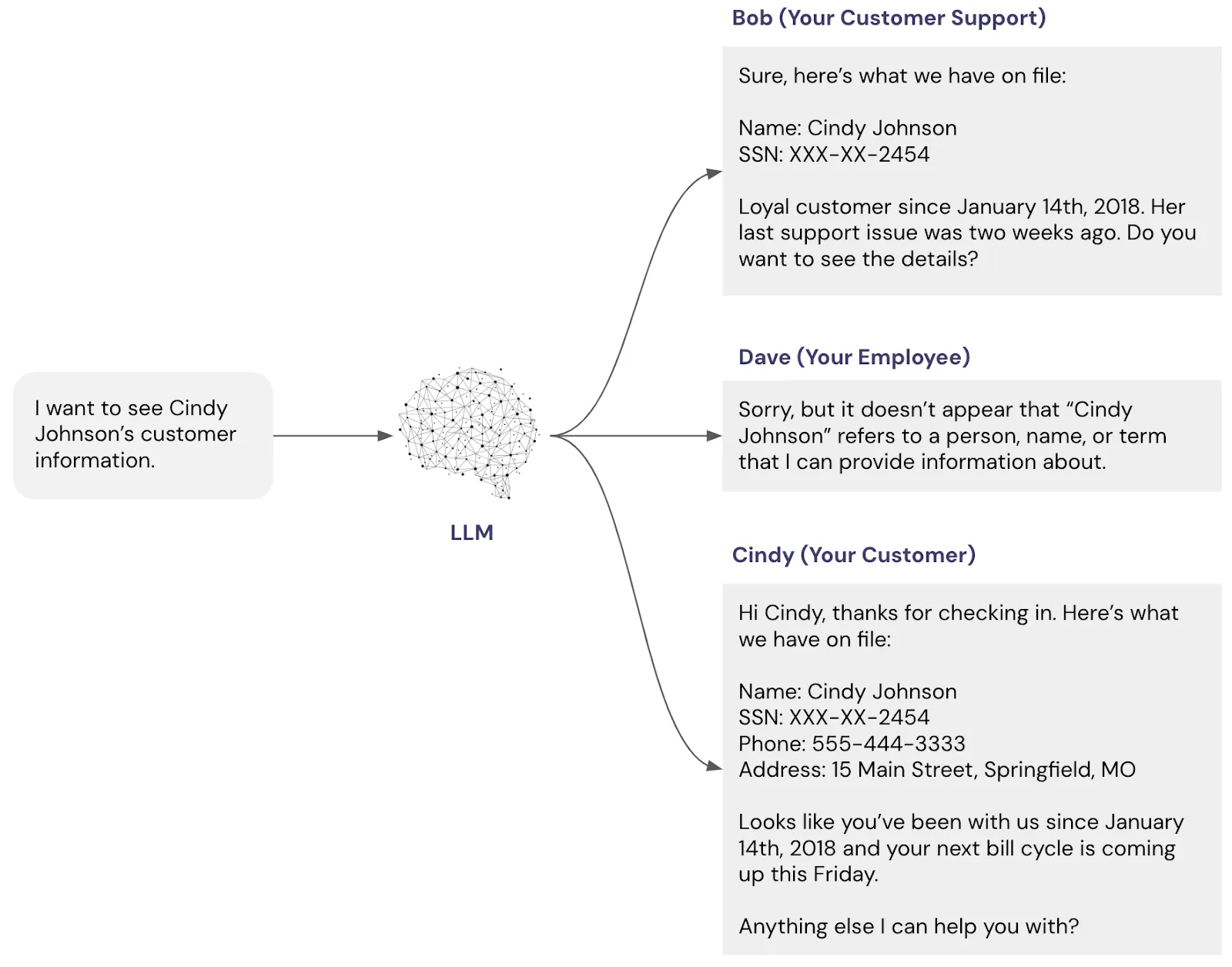
In Microsoft’s Security Best Practices for GenAI Applications in Azure, they state “Implement data masking or redaction techniques to hide sensitive data or replace it with obfuscated values in non-production environments or when sharing data for testing or troubleshooting purposes.” The private LLM approach doesn’t give you out of the box features like this.
After you give a model data, it’s very difficult to control how it uses that information, which means an engineer, customer service, or sales team member could use AI to access sensitive information like salaries, confidential projects, or customer details depending on what’s in your training set.
Lack of Enterprise Governance
A significant hurdle with private LLM is the lack of inherent support for comprehensive auditing and logging, crucial for transparent and compliant operation. Establishing these systems is complex and resource-heavy, necessitating sophisticated frameworks for recording interactions, ensuring data security, and maintaining accountability.
Additionally, creating guardrails to prevent misuse requires a deep understanding of the LLM's capabilities and vulnerabilities, alongside vigilant monitoring to counteract emerging threats. Implementing these controls requires advanced understanding of both the model's capabilities and potential vulnerabilities, as well as ongoing monitoring to adapt to new threats or misuse patterns. This level of oversight is difficult to achieve without significant expertise and continuous effort.
In B2B contexts, demonstrating that models are trained on de-identified data is vital, as is confirming end-use consent in B2C uses. These practices, including data anonymization, minimization, and masking, are essential for protecting privacy and adhering to data protection laws.
Implementing these governance measures—auditing, logging, consent management, and data protection—poses a significant challenge. Organizations must allocate substantial resources to develop these capabilities internally, or else risk non-compliance, security vulnerabilities, and erosion of customer trust. Without proper enterprise governance controls, private LLM deployments may fall short of meeting the high standards required for ethical, secure, and compliant operation.
Difficult Comply with Privacy Regulations
One of the major drawbacks of LLMs is their inability to selectively remove (or “unlearn”) individual data points such as an individual’s name or date of birth. This limitation creates long-term risks for businesses utilizing these systems. For example, the EU’s GDPR grants individuals the right to access, rectify, and erase their personal data – which can be very difficult to accomplish if that data is found within a LLM. GDPR also grants individuals the right to object to automated decision-making.
Moreover, complying with data localization requirements becomes nearly impossible when using a global LLM system. For example, meeting the stringent conditions of China's Personal Information Protection Law (PIPL) regarding the transfer of personal information outside of China poses significant difficulties if this information is present in a global LLM system. Microsoft’s documentation calls out that training and fine-tuning results in a single, consolidated model. If you’re incorporating customer data from various regions, this approach undermines data residency compliance.
Data Subject Access Requests (DSARs) under GDPR and other laws add another layer of complexity. In the EU and California, individuals have the right to request access to their personal data, but complying with such requests proves challenging if that data has been processed by LLMs. LLMs are often distributed across multiple servers, which makes identifying and extracting the specific data associated with an individual arduous and error-prone.
Based on CPRA, GDPR, and other data privacy laws, customers have the right to request the deletion of their data. Microsoft stated that fine-tuned models can be deleted, but that's the deletion of the entire model, not the deletion of a specific data subject request. Additionally, while OpenAI is considered to be GDPR and SOC2 compliant, complying with other regulatory measures such as HIPAA are up to customers.
Considering the intricate privacy and compliance landscape and the complexity of LLMs, the most practical approach to maintaining compliance is to prevent sensitive data from entering the model altogether. By implementing stringent data handling practices, businesses can mitigate the privacy risks associated with LLMs, while also maintaining the utility of the model.
Increased Maintenance and Compute Cost
The very nature of LLMs, with their vast neural networks requiring extensive computational resources, means that organizations must be prepared to invest heavily in high-performance hardware. This not only involves high upfront costs for acquiring state-of-the-art servers and GPUs but also accounts for the ongoing costs related to energy consumption, cooling, and potential hardware upgrades to keep up with advancing technology.
Beyond the direct hardware costs, organizations taking on the operation of private LLMs also shoulder the responsibility of comprehensive infrastructure maintenance. This encompasses a wide range of tasks from routine system administration, ensuring the continuous operation of servers and network infrastructure, to more specialized tasks such as implementing security updates and patches. Given the critical importance of data security and privacy, particularly in environments handling sensitive or proprietary information, the burden of maintaining robust security measures can’t be understated. This requires constant vigilance and a proactive approach to safeguard against evolving cybersecurity threats.
Machine learning and LLMs introduce an additional layer of complexity in terms of model maintenance. Updating and fine-tuning the model to improve its performance or to adapt to new data involves not just significant computational resources but also specialized knowledge in machine learning techniques. These updates are crucial for maintaining the relevance and accuracy of the model over time but necessitate ongoing investment in both expertise and compute capacity.
The financial investment required for high-performance hardware, the operational burden of infrastructure maintenance, the complexity of ensuring robust security, and the need for continuous model updates and technical expertise collectively represent a significant undertaking for any organization. These factors must be carefully considered and addressed to ensure the successful and sustainable operation of a private LLM.
Difficult to Run Multiple Models
There's a growing trend towards using multiple LLMs to help improve performance. This multiplicity, however, introduces its own set of challenges, particularly for organizations that opt to run these models privately within their own cloud environments.
As described above, running a single LLM requires substantial processing power, memory, and storage, and scaling. With multiple LLM, you are amplifying this problem to accommodate multiple models. This scenario leads to exponential increases in hardware costs and energy consumption, making it a costly endeavor for organizations. Furthermore, the complexity of orchestrating these resources efficiently, ensuring that each model operates optimally without interfering with the others, adds another layer of difficulty in system administration and resource allocation.
Each model may have its own set of dependencies, vulnerabilities, and updating schedules. This diversity necessitates a broad range of technical expertise and meticulous planning to manage effectively.
Learn how to protect sensitive data in AI applications. Download whitepaper →
How Skyflow Protects Sensitive Data in Any LLM
Clearly there’s a lot you need to take into account when navigating data privacy and LLMs that private LLMs don't directly solve. Skyflow Data Privacy Vault is designed to help you harness the full potential of LLMs for diverse use cases while ensuring the utmost security and data privacy.
Skyflow offers comprehensive privacy-preserving solutions that help you keep sensitive data out of LLMs, addressing privacy concerns around inference and LLM training:
- Model Training: Skyflow enables privacy-safe model training by excluding sensitive data from datasets used in the model training process.
- Inference: Skyflow also protects the privacy of sensitive data from being collected by inference from prompts or user-provided files used for RAG.
- Intelligent Guardrails: Ensure responsible and ethical use of language models. Guardrails prevent harmful output, address bias and fairness, and help achieve compliance with policies and regulations.
- Governance and Access Control: Define precise access policies around de-identified data, controlling who sees what, when, and where based on who is providing the prompt. Authorized users receive the data they need, only for the exact amount of time they need it. All access is logged and available for auditing purposes.
- Integrated Compute Environment: Skyflow Data Privacy Vault seamlessly integrates into existing data infrastructure to add an effective layer of data protection. Your Skyflow vault protects all sensitive data by preventing plaintext sensitive data from flowing into LLMs, only revealing sensitive data to authorized users as model outputs are shared with those users.
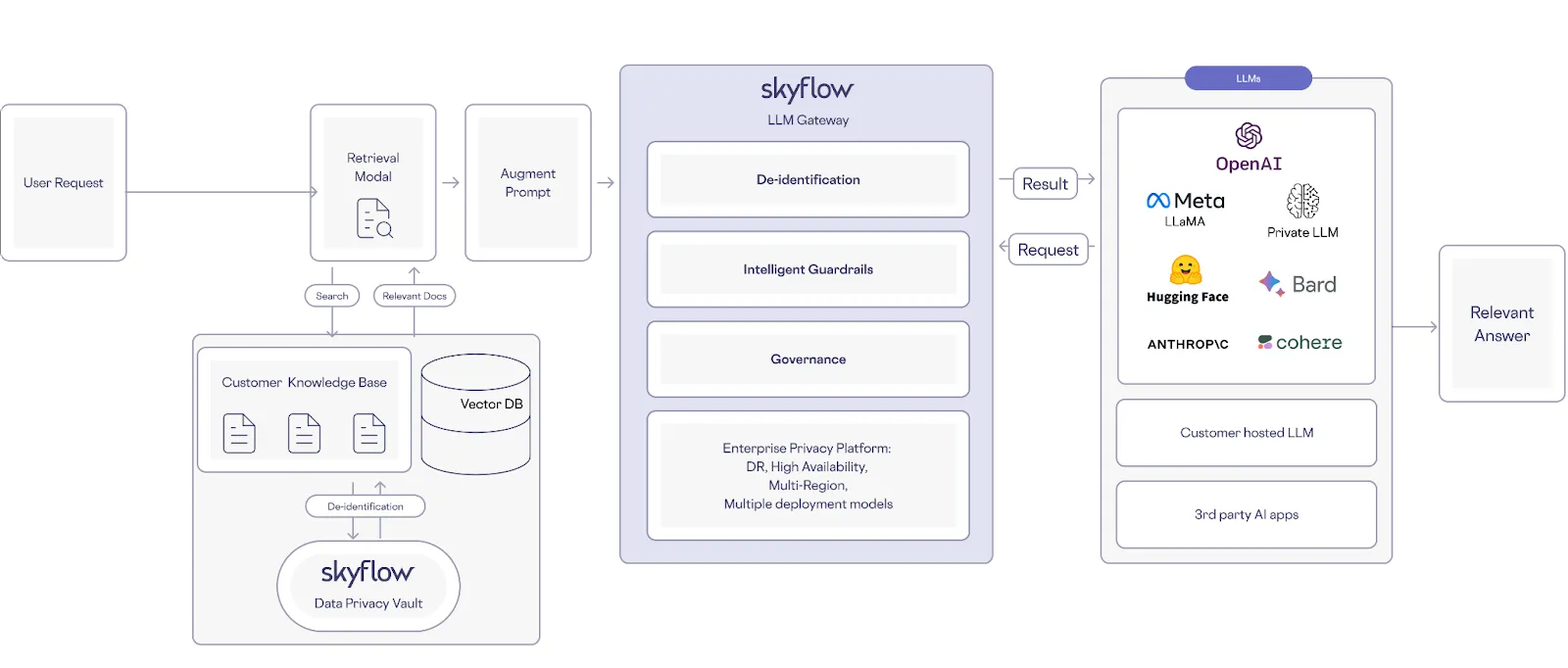
Skyflow de-identifies sensitive data through tokenization or masking and provides a sensitive data dictionary that lets businesses define terms that are sensitive and should not be fed into LLMs. It also supports data privacy compliance requirements, including data residency.
Because sensitive data is swapped with non-exploitable vault tokens (which are distinct from LLM tokens), authorized users get a seamless experience. And because access to detokenize vault-generated tokens is subject to strict zero-trust access controls, unauthorized users won’t get access to sensitive data that are referenced in LLM responses. This means that lower-privileged users can’t access sensitive data, because it isn’t in your LLM, and they don’t have access to redeem the tokens.
This also means that you can have a global LLM without having to worry about data residency as the LLM doesn’t store or have access to regulated data.
This solution delivers the data privacy and data governance that people expect from private LLMs, but that aren’t yet available as integrated features of these platforms.
Try Skyflow
Protecting data privacy in LLMs is essential to help ensure that this technology is used responsibly and ethically. While private LLM provides some advantages over public LLMs in terms of customization, running your model within your own environment alone doesn’t help address fundamental data privacy issues. Additionally, you could be taking on a lot of additional cost in terms of compute and maintenance.
By using Skyflow, companies can protect the privacy and security of sensitive data, protect user privacy, and retain user trust when using LLM-based AI systems in a way that isn’t possible simply by adopting a private LLM.